IBM Watson から提供されている AI 系 API の中で、自然言語テキストを分類する機能を持った NLC(Natural Language Classifier) の提供が終了することがアナウンスされました。2021年9月9日までは新規インスタンスの作成が可能ですが、それ以降の新規作成はできません。また既存インスタンスは2022年8月8日まで利用できますが、それまでに移行先を決め、その移行作業を済ませておく必要があります:
https://cloud.ibm.com/docs/natural-language-classifier?topic=natural-language-classifier-migrating
NLC は個人的にも IBM Watson を使い始めるきっかけになった API で、思い入れの深いサービスだったりします。NLC を使って作った多くのデモアプリは WordCamp Tokyo や特定のお客様向けに作ったものを含めて多くの場で紹介させていただきました。感慨深いものがあります。
上記アナウンス内で、公式な移行先として同じ IBM Watson の NLU(Natural Language Understandings) が紹介されています。が、具体的な移行手順や方法に関する情報が少ないこともあり、実際に自分が NLC API を使って開発したアプリケーションをどのように NLU に移行すればよいかがわかりにくいように感じました。 自分自身の場合は普段 Node.js を使ってアプリケーションを開発しているのですが、Node.js の場合は具体的にどのようにすれば NLC から NLU へ移行できるか? という調査をしてみました。実際に Node.js でプログラムを書き、具体的にはまず NLC API を使って、
・認証
・日本語データ学習
・学習状況確認
・問い合わせ(分類)
・学習の削除
といった5種類のオペレーションを行えるようなアプリケーションを作りました。 そしてそのアプリケーションを NLC から NLU へ実際に移植する、といった作業を行ってみました。結論として上記5種類のオペレーションは NLU でも NLC 同様に行うことができました。ただ API には互換性はなく、ソースコードレベルではそれなりに変更が必要になるため、どの程度の変更が必要になるのか、という調査の意味も含めて作業した様子を以下に紹介します。
なお、NLC は IBM Cloud の(無料版の)ライトアカウント向けには提供されていない API である点に注意してください。ライトアカウントの状態で NLC の新規インスタンスを作成することは(9月9日以前であっても)できません。ベーシック以上の(有償の)アカウントであれば無料枠含めて提供されている API です。 一方の NLU はライトアカウントでも利用することが可能ですが、ライトアカウントの場合はライトプラン(無料)の NLU を1インスタンスのみ作成でき、1インスタンスにつき1モデルだけ学習で作成できます(要は複数の学習モデルを作成するにはベーシック以上のアカウントで、有料プランを選択する必要があります)。
【サンプルコードのダウンロード】
以下で紹介する一連の手順を行うための Node.js 用サンプルコードを作って公開しました:
https://github.com/dotnsf/nlc2nlu
git clone するかコードをダウンロード&展開してください。以下の3つのフォルダが含まれています:
csvtool は実際に NLC や NLU で使うサンプルの学習データを作成するツールです。NLC や NLU を既に使っていて、どのような学習データを用意すればよいかわかっている場合は、ご自身で学習データ(CSV ファイル)を用意いただいてもかまいませんが、そうでない人向けに Yahoo! ニュースの RSS(https://news.yahoo.co.jp/rss) を使って、その場で学習データを作成できるようにしたものです。
nlc と nlu は名前の通りで、学習データを学習させて、学習状況を確認しながら学習が完了したら、実際に適当な日本語テキストを送信して、学習データに基づくテキスト分類を実施します。また実施後に学習データを削除する、といった操作も可能です。これらの内容を NLC および NLU それぞれで行えるようにしたツールが含まれています。
ではそれぞれのフォルダの使い方を説明します。
【csvtool : 学習データの用意】
csvtool/csvgenerator.js で Yahoo! ニュース RSS から学習データとしての CSV ファイルを作成します。NLC / NLU とも学習データは以下のフォーマットの CSV ファイルを用意します※:
※ NLU は JSON フォーマットでも学習データを準備して読み込むことが可能ですが、NLC からの移植を考えると NLC と同じ条件で学習データを用意するべきと考え、同じ CSV ファイルを学習データとして使うことにします。
このような(NLC 向けの)学習データを既にお持ちであればそれを使って後述の作業を続けていただいてもかまいませんが、多くの人はそのような学習データを持っていないと思うので、新たに用意することにします。その場合は csvtool/csvgenerator.js を使います。
実行方法は単純で、csvtool フォルダに移動し、まず普通に $ npm install を実行して依存ライブラリを導入します:
その後、node コマンドでこのファイルを実行します。実行コマンドの最後に出力先 CSV ファイル名を指定します(以下の例だと同一フォルダ内の csvfile.csv):
実行したタイミングで Yahoo! ニュースの RSS を参照して、その時点のニュースを取得して CSV ファイルに書き出します。なお、このツールでは「経済」、「IT」、「エンタメ」、「科学」、「スポーツ」の5つのカテゴリーのニュースを収集します。 ツールの実行が完了すると、指定した CSV ファイルが以下のような内容で生成されます:
ここまでできれば学習データの準備は完了です。ではこのデータを NLC と NLU それぞれで学習させて問い合わせる、という作業をこれ以降で行っていきましょう。
【nlc : NLC で操作】
まずは NLC API を使って開発したアプリでこのデータを学習させ、NLC API を使って問い合わせを行ってみましょう。先ほどダウンロードしたソースコードの nlc フォルダ内にある nlc/nlc.js ファイルを使って操作します(このコードの内容については後述します)。まずは csvgenerator.js の時と同様に $ npm install を実行して依存ライブラリを導入します:
その後、node コマンドでこのファイルを実行します。この nlc.js はコマンドラインアプリケーションで、その実行時パラメータによって「データ学習」、「学習状況確認」、「問い合わせ(分類)」、「学習データ削除」の4つを行うことができます:
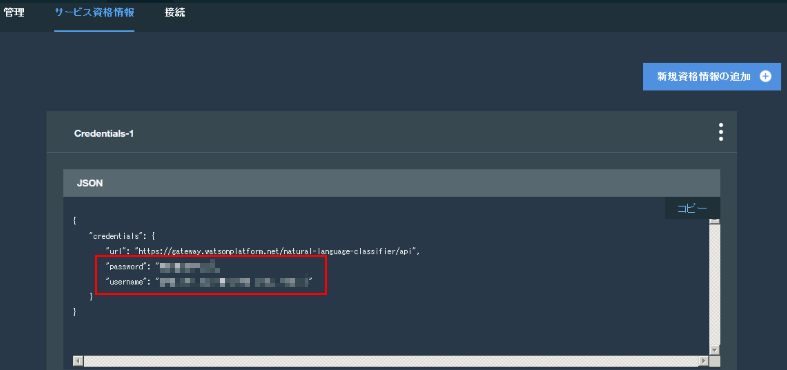
では実際に nlc ツールを使いながら操作を確認してみましょう。まずは IBM Cloud にウェブブラウザでログインして、NLC インスタンスを作成し、「サービス資格情報」(を必要であれば作成して)の内容を確認します:
この中に apikey 属性値と url 属性値が含まれているので、それらの値を nlc/settings.js ファイル内の exports.nlc_apiKey 値および exports.nlc_url 値にそれぞれコピーして保存します:
これで実行前の準備は完了しました。早速「データ学習」を実行してみます。「データ学習」は(前述の作業で用意した)学習データ CSV ファイルを指定して、$ node nlc create [csvfilename] を実行します。先ほどの手順で ../csvtool/csvfile.csv というファイルが作られている場合は以下のように指定して実行します:
これで指定した CSV ファイルを元にする学習が開始されます。この学習が完了すると問い合わせ(分類)ができるようになりますが、完了しているかどうかを確認するには以下のコマンドを実行します:
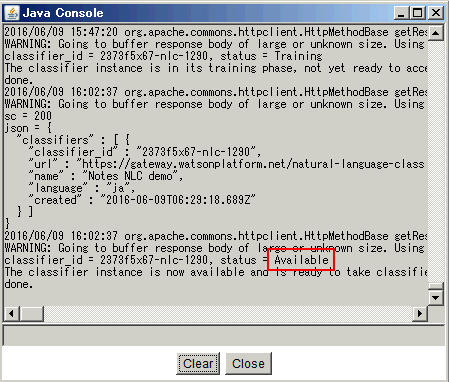
実行結果は以下のような JSON が表示されますが、この中の status 欄が "available" となっていれば学習は完了しています(データ量にもよりますが、自分が試した時はこうなるまでおよそ 10 分程度かかりました)。同時に表示されている classifier_id の値はこの後で使うので合わせてメモしておきましょう:
学習が完了したら改めて日本語テキストを指定して、その内容がどのカテゴリーに属しているのかを分類してみましょう。日本語テキストと上述で確認した classifier_id 値を指定して、以下のようなコマンドを実行します:
すると以下のような結果が表示されます。指定した日本語テキスト(「パッキャオがんばれ」)を学習データに含まれていたカテゴリー(今回作ったものだと「経済」、「IT」、「エンタメ」、「科学」、「スポーツ」)のどれに相当するものかを識別して、その可能性の高い順に結果を返しています。この例では「スポーツ」の可能性が 50% 強である、と判断されているようです:
作成した学習データを IBM Watson NLC から削除するには以下のコマンドを実行します:
ここまでのオペレーションで「データ学習」、「学習状況確認」、「問い合わせ(分類)」、「学習データ削除」の4つを NLC API を使って実現し、そのアプリケーションを実行する方法を紹介しました。
【nlu : NLU で操作】
では改めてこの nlc アプリケーションを NLU API で作り直し、同じ4つのオペレーションができることを確認してみます。先ほどダウンロードしたソースコードの nlu フォルダ内にある nlu/nlu.js ファイルを使って操作します(このコードの内容については後述します)。まずは csvgenerator.js の時と同様に $ npm install を実行して依存ライブラリを導入します:
その後、node コマンドでこのファイルを実行します。この nlu.js もコマンドラインアプリケーションで、その実行時パラメータによって「データ学習」、「学習状況確認」、「問い合わせ(分類)」、「学習データ削除」の4つを行うことができます:
※前述の NLC では問い合わせ時に "classify(分類)" という命令を指定していましたが、NLU では同じ作業を "analyze(解析)" と表現しているようです。またパラメータとして指定する ID も NLC では "classifier_id(分類ID)" だったのですが、NLU では "model_id(モデルID)" という表現になっていました。
では実際に nlu ツールを使いながら操作を確認してみましょう。まずは IBM Cloud にウェブブラウザでログインして、NLU インスタンスを作成し、「サービス資格情報」(を必要であれば作成して)の内容を確認します:
この中に apikey 属性値と url 属性値が含まれているので、それらの値を nlu/settings.js ファイル内の exports.nlc_apiKey 値および exports.nlc_url 値にそれぞれコピーして保存します:
これで実行前の準備は完了しました。早速「データ学習」を実行してみます。「データ学習」は(前述の作業で用意した)学習データ CSV ファイルを指定して、$ node nlu create [csvfilename] を実行します。先ほどの手順で ../csvtool/csvfile.csv というファイルが作られている場合は以下のように指定して実行します:
これで指定した CSV ファイルを元にする学習が開始されます。この学習が完了すると問い合わせ(分類)ができるようになりますが、完了しているかどうかを確認するには以下のコマンドを実行します:
実行結果は以下のような JSON が表示されますが、この中の status 欄が "available" となっていれば学習は完了しています。同時に表示されている model_id の値はこの後で使うので合わせてメモしておきましょう。この辺りまでは前述の NLC の時とほぼ同様ですね:
学習が完了したら改めて日本語テキストを指定して、その内容がどのカテゴリーに属しているのかを分類してみましょう。NLC では "classify" と指定していた部分は NLU では "analyze" となる点に注意してください。日本語テキストと上述で確認した model_id 値を指定して、以下のようなコマンドを実行します:
すると以下のような結果が表示されます。指定した日本語テキストを学習データに含まれていたカテゴリー(今回作ったものだと「経済」、「IT」、「エンタメ」、「科学」、「スポーツ」)のどれに相当するものかを識別して、その可能性の高い順に結果を返しています。同じ学習データで同じ問い合わせをして、こちらでも「スポーツ」の可能性が高いと判定されていますが、その確率や2位以下の結果には違いがあることがわかります:
作成した学習データを IBM Watson NLU から削除するには以下のコマンドを実行します:
ここまでのオペレーションで NLC 同様に NLU でも「データ学習」、「学習状況確認」、「問い合わせ(分類)」、「学習データ削除」の4つを API で実現し、そのアプリケーションを実行する方法を紹介しました。とりあえず、この4つのオペレーションについては NLC から NLU へ移行することはできそうだ、という感触が持てる結果になりました。
【API レベルの移行作業】
同じオペレーションを行う NLC のツールと NLU のツールを実際に Node.js + IBM Watson SDK で開発してわかったことを記載しておきます。
まず API に互換性はありません。IAM を使った認証部分についてはほぼ同じなのですが、今回行った4つのオペレーションを実現するためのそれぞれの API は NLC のものと NLU のものは全く異なります:
パラメータの指定方法など、詳しくはソースコード(nlc/nlc.js / nlu/nlu.js)を参照していただきたいのですが、大まかには上記表のような関数の違いがあります。特に Node.js + IBM Watson SDK を使っているアプリケーションにおいて NLC から NLU へ移植する場合は、表の左列にある関数を使っている箇所を右列の関数に置き換える、というのが大まかな流れになると思います(実際にはパラメータの指定方法だったり、返り値のフォーマットの違いもあったりするので、単なる文字列置換というわけにはいかないと思います)。また NLC では「分類器(Classifier)」と呼んでいたものが NLU だと「分類モデル(ClassficationModel)」と呼び名が変わっていたりもするので、資料を参照する場合の注意も必要だと思います。
加えて、上記のように NLC を使って問い合わせた結果と NLU に移植後に問い合わせた結果は必ずしも同じ結果とはいきません。このあたりの整合性についても移植の前後で意識しておく必要があります。
とはいえ、少なくとも API のレベルで NLC から NLU へアプリケーションを移植することは不可能ではなさそう、という感触も得ることができました。主要なオペレーションに関しては上述の表を使って関数を新しいものに置き換え、実行結果のフォーマットの違いをプログラミング内で吸収することができれば、ある程度の実現目途は立ちそうだと思っています。
今回の NLC のサービス終了自体は残念ではありますが、一方で見方を変えると、これまで有償サービスでしか提供されていなかった NLC の機能が、無料のライトプランで使える NLU でも利用できるようになった、とも言えます。API レベルでの互換性はありませんが、機能的には珍しくこれまでの機能の多くが移植されていて、「アプリケーションの作り変え」による対応が可能なレベルでマイグレーションができるようになっていると感じました。「料金的にも発展的なサービス統合」であると感じています。
Node.js 以外の開発言語での場合や、IBM Watson SDK の利用有無の違いをどこまで吸収できるかまでを調査したわけではないのですが、一部の言語については後述の参考資料の中でサンプルコードもあるようなので、別環境においてもぜひ挑戦していただき、情報が共有されていくことを願っています。
【参考資料】
https://cloud.ibm.com/docs/natural-language-classifier?topic=natural-language-classifier-migrating
https://cloud.ibm.com/apidocs/natural-language-understanding?code=node
https://cloud.ibm.com/docs/natural-language-classifier?topic=natural-language-classifier-migrating
NLC は個人的にも IBM Watson を使い始めるきっかけになった API で、思い入れの深いサービスだったりします。NLC を使って作った多くのデモアプリは WordCamp Tokyo や特定のお客様向けに作ったものを含めて多くの場で紹介させていただきました。感慨深いものがあります。
上記アナウンス内で、公式な移行先として同じ IBM Watson の NLU(Natural Language Understandings) が紹介されています。が、具体的な移行手順や方法に関する情報が少ないこともあり、実際に自分が NLC API を使って開発したアプリケーションをどのように NLU に移行すればよいかがわかりにくいように感じました。 自分自身の場合は普段 Node.js を使ってアプリケーションを開発しているのですが、Node.js の場合は具体的にどのようにすれば NLC から NLU へ移行できるか? という調査をしてみました。実際に Node.js でプログラムを書き、具体的にはまず NLC API を使って、
・認証
・日本語データ学習
・学習状況確認
・問い合わせ(分類)
・学習の削除
といった5種類のオペレーションを行えるようなアプリケーションを作りました。 そしてそのアプリケーションを NLC から NLU へ実際に移植する、といった作業を行ってみました。結論として上記5種類のオペレーションは NLU でも NLC 同様に行うことができました。ただ API には互換性はなく、ソースコードレベルではそれなりに変更が必要になるため、どの程度の変更が必要になるのか、という調査の意味も含めて作業した様子を以下に紹介します。
なお、NLC は IBM Cloud の(無料版の)ライトアカウント向けには提供されていない API である点に注意してください。ライトアカウントの状態で NLC の新規インスタンスを作成することは(9月9日以前であっても)できません。ベーシック以上の(有償の)アカウントであれば無料枠含めて提供されている API です。 一方の NLU はライトアカウントでも利用することが可能ですが、ライトアカウントの場合はライトプラン(無料)の NLU を1インスタンスのみ作成でき、1インスタンスにつき1モデルだけ学習で作成できます(要は複数の学習モデルを作成するにはベーシック以上のアカウントで、有料プランを選択する必要があります)。

【サンプルコードのダウンロード】
以下で紹介する一連の手順を行うための Node.js 用サンプルコードを作って公開しました:
https://github.com/dotnsf/nlc2nlu
git clone するかコードをダウンロード&展開してください。以下の3つのフォルダが含まれています:
|- csvtool |- nlc |- nlu
csvtool は実際に NLC や NLU で使うサンプルの学習データを作成するツールです。NLC や NLU を既に使っていて、どのような学習データを用意すればよいかわかっている場合は、ご自身で学習データ(CSV ファイル)を用意いただいてもかまいませんが、そうでない人向けに Yahoo! ニュースの RSS(https://news.yahoo.co.jp/rss) を使って、その場で学習データを作成できるようにしたものです。
nlc と nlu は名前の通りで、学習データを学習させて、学習状況を確認しながら学習が完了したら、実際に適当な日本語テキストを送信して、学習データに基づくテキスト分類を実施します。また実施後に学習データを削除する、といった操作も可能です。これらの内容を NLC および NLU それぞれで行えるようにしたツールが含まれています。
ではそれぞれのフォルダの使い方を説明します。
【csvtool : 学習データの用意】
csvtool/csvgenerator.js で Yahoo! ニュース RSS から学習データとしての CSV ファイルを作成します。NLC / NLU とも学習データは以下のフォーマットの CSV ファイルを用意します※:
テキスト,このテキストが属するカテゴリー テキスト,このテキストが属するカテゴリー テキスト,このテキストが属するカテゴリー :
※ NLU は JSON フォーマットでも学習データを準備して読み込むことが可能ですが、NLC からの移植を考えると NLC と同じ条件で学習データを用意するべきと考え、同じ CSV ファイルを学習データとして使うことにします。
このような(NLC 向けの)学習データを既にお持ちであればそれを使って後述の作業を続けていただいてもかまいませんが、多くの人はそのような学習データを持っていないと思うので、新たに用意することにします。その場合は csvtool/csvgenerator.js を使います。
実行方法は単純で、csvtool フォルダに移動し、まず普通に $ npm install を実行して依存ライブラリを導入します:
$ cd csvtool $ npm install
その後、node コマンドでこのファイルを実行します。実行コマンドの最後に出力先 CSV ファイル名を指定します(以下の例だと同一フォルダ内の csvfile.csv):
$ node csvgenerator csvfile.csv
実行したタイミングで Yahoo! ニュースの RSS を参照して、その時点のニュースを取得して CSV ファイルに書き出します。なお、このツールでは「経済」、「IT」、「エンタメ」、「科学」、「スポーツ」の5つのカテゴリーのニュースを収集します。 ツールの実行が完了すると、指定した CSV ファイルが以下のような内容で生成されます:
RSS から取り出したニュース内容,このニュースのカテゴリー RSS から取り出したニュース内容,このニュースのカテゴリー RSS から取り出したニュース内容,このニュースのカテゴリー :
ここまでできれば学習データの準備は完了です。ではこのデータを NLC と NLU それぞれで学習させて問い合わせる、という作業をこれ以降で行っていきましょう。
【nlc : NLC で操作】
まずは NLC API を使って開発したアプリでこのデータを学習させ、NLC API を使って問い合わせを行ってみましょう。先ほどダウンロードしたソースコードの nlc フォルダ内にある nlc/nlc.js ファイルを使って操作します(このコードの内容については後述します)。まずは csvgenerator.js の時と同様に $ npm install を実行して依存ライブラリを導入します:
$ cd nlc $ npm install
その後、node コマンドでこのファイルを実行します。この nlc.js はコマンドラインアプリケーションで、その実行時パラメータによって「データ学習」、「学習状況確認」、「問い合わせ(分類)」、「学習データ削除」の4つを行うことができます:
$ node nlc create [csvfilename] ・・・データ学習 $ node nlc status ・・・学習状況確認 $ node nlc classify [日本語テキスト] [classifier_id] ・・・問い合わせ(分類) $ node nlc delete [classifier_id] ・・・学習データ削除
では実際に nlc ツールを使いながら操作を確認してみましょう。まずは IBM Cloud にウェブブラウザでログインして、NLC インスタンスを作成し、「サービス資格情報」(を必要であれば作成して)の内容を確認します:
この中に apikey 属性値と url 属性値が含まれているので、それらの値を nlc/settings.js ファイル内の exports.nlc_apiKey 値および exports.nlc_url 値にそれぞれコピーして保存します:
exports.nlc_apiKey = 'サービス資格情報内の apikey 属性値'; exports.nlc_url = 'サービス資格情報内の url 属性値'; exports.nlc_name = 'nlc2nlu'; exports.nlc_language = 'ja';
これで実行前の準備は完了しました。早速「データ学習」を実行してみます。「データ学習」は(前述の作業で用意した)学習データ CSV ファイルを指定して、$ node nlc create [csvfilename] を実行します。先ほどの手順で ../csvtool/csvfile.csv というファイルが作られている場合は以下のように指定して実行します:
$ node nlc create ../csvtool/csvfile.csv
これで指定した CSV ファイルを元にする学習が開始されます。この学習が完了すると問い合わせ(分類)ができるようになりますが、完了しているかどうかを確認するには以下のコマンドを実行します:
$ node nlc status
実行結果は以下のような JSON が表示されますが、この中の status 欄が "available" となっていれば学習は完了しています(データ量にもよりますが、自分が試した時はこうなるまでおよそ 10 分程度かかりました)。同時に表示されている classifier_id の値はこの後で使うので合わせてメモしておきましょう:
{
"status": 200,
"statusText": "OK",
"headers": {
"content-type": "application/json",
"x-xss-protection": "1",
"content-security-policy": "default-src 'none'",
"x-content-type-options": "nosniff",
"cache-control": "no-cache, no-store",
"pragma": "no-cache",
"expires": "0",
"content-length": "428",
"strict-transport-security": "max-age=31536000; includeSubDomains;",
"x-dp-watson-tran-id": "e6168d25-5640-4790-a1f1-02ff089dd869",
"x-request-id": "e6168d25-5640-4790-a1f1-02ff089dd869",
"x-global-transaction-id": "e6168d25-5640-4790-a1f1-02ff089dd869",
"server": "watson-gateway",
"x-edgeconnect-midmile-rtt": "7",
"x-edgeconnect-origin-mex-latency": "22",
"date": "Tue, 24 Aug 2021 05:48:32 GMT",
"connection": "close"
},
"result": {
"classifier_id": "e87efex297-nlc-650",
"name": "nlc2nlu",
"language": "ja",
"created": "2021-08-24T05:45:20.090Z",
"url": "https://api.jp-tok.natural-language-classifier.watson.cloud.ibm.com/instances/f738a110-248b-419c-b771-8e6cbd45ee93/v1/classifiers/e87efex297-nlc-650",
"status_description": "The classifier instance is now available and is ready to take classifier requests.",
"status": "Available"
}
}
学習が完了したら改めて日本語テキストを指定して、その内容がどのカテゴリーに属しているのかを分類してみましょう。日本語テキストと上述で確認した classifier_id 値を指定して、以下のようなコマンドを実行します:
$ node nlc classify [日本語テキスト] [classifier_id]
すると以下のような結果が表示されます。指定した日本語テキスト(「パッキャオがんばれ」)を学習データに含まれていたカテゴリー(今回作ったものだと「経済」、「IT」、「エンタメ」、「科学」、「スポーツ」)のどれに相当するものかを識別して、その可能性の高い順に結果を返しています。この例では「スポーツ」の可能性が 50% 強である、と判断されているようです:
$ node nlc classify パッキャオがんばれ e87efex297-nlc-650
{ "status": 200, "statusText": "OK", "headers": { "content-type": "application/json", "x-xss-protection": "1", "content-security-policy": "default-src 'none'", "x-content-type-options": "nosniff", "cache-control": "no-cache, no-store", "pragma": "no-cache", "expires": "0", "content-length": "679", "strict-transport-security": "max-age=31536000; includeSubDomains;", "x-dp-watson-tran-id": "102350df-e1d0-4568-ae10-6e72ba1b44b0", "x-request-id": "102350df-e1d0-4568-ae10-6e72ba1b44b0", "x-global-transaction-id": "102350df-e1d0-4568-ae10-6e72ba1b44b0", "server": "watson-gateway", "x-edgeconnect-midmile-rtt": "7", "x-edgeconnect-origin-mex-latency": "43", "date": "Tue, 24 Aug 2021 05:51:22 GMT", "connection": "close" }, "result": { "classifier_id": "e87efex297-nlc-650", "url": "https://api.jp-tok.natural-language-classifier.watson.cloud.ibm.com/instances/f738a110-248b-419c-b771-8e6cbd45ee93/v1/classifiers/e87efex297-nlc-650", "text": "パッキャオがんばれ", "top_class": "スポーツ", "classes": [ { "class_name": "スポーツ", "confidence": 0.5022989563107099 }, { "class_name": "エンタメ", "confidence": 0.20692538301831817 }, { "class_name": "経済", "confidence": 0.1200947580342344 }, { "class_name": "科学", "confidence": 0.11456564859743573 }, { "class_name": "IT", "confidence": 0.05611525403930185 } ] } }
作成した学習データを IBM Watson NLC から削除するには以下のコマンドを実行します:
$ node nlc delete [classifier_id]
ここまでのオペレーションで「データ学習」、「学習状況確認」、「問い合わせ(分類)」、「学習データ削除」の4つを NLC API を使って実現し、そのアプリケーションを実行する方法を紹介しました。
【nlu : NLU で操作】
では改めてこの nlc アプリケーションを NLU API で作り直し、同じ4つのオペレーションができることを確認してみます。先ほどダウンロードしたソースコードの nlu フォルダ内にある nlu/nlu.js ファイルを使って操作します(このコードの内容については後述します)。まずは csvgenerator.js の時と同様に $ npm install を実行して依存ライブラリを導入します:
$ cd nlc $ npm install
その後、node コマンドでこのファイルを実行します。この nlu.js もコマンドラインアプリケーションで、その実行時パラメータによって「データ学習」、「学習状況確認」、「問い合わせ(分類)」、「学習データ削除」の4つを行うことができます:
$ node nlu create [csvfilename] ・・・データ学習 $ node nlu status ・・・学習状況確認 $ node nlu analyze [日本語テキスト] [model_id] ・・・問い合わせ(分類) $ node nlu delete [model_id] ・・・学習データ削除
※前述の NLC では問い合わせ時に "classify(分類)" という命令を指定していましたが、NLU では同じ作業を "analyze(解析)" と表現しているようです。またパラメータとして指定する ID も NLC では "classifier_id(分類ID)" だったのですが、NLU では "model_id(モデルID)" という表現になっていました。
では実際に nlu ツールを使いながら操作を確認してみましょう。まずは IBM Cloud にウェブブラウザでログインして、NLU インスタンスを作成し、「サービス資格情報」(を必要であれば作成して)の内容を確認します:

この中に apikey 属性値と url 属性値が含まれているので、それらの値を nlu/settings.js ファイル内の exports.nlc_apiKey 値および exports.nlc_url 値にそれぞれコピーして保存します:
exports.nlu_apiKey = 'サービス資格情報内の apikey 属性値'; exports.nlu_url = 'サービス資格情報内の url 属性値'; exports.nlu_name = 'nlc2nlu'; exports.nlu_language = 'ja';
これで実行前の準備は完了しました。早速「データ学習」を実行してみます。「データ学習」は(前述の作業で用意した)学習データ CSV ファイルを指定して、$ node nlu create [csvfilename] を実行します。先ほどの手順で ../csvtool/csvfile.csv というファイルが作られている場合は以下のように指定して実行します:
$ node nlu create ../csvtool/csvfile.csv
これで指定した CSV ファイルを元にする学習が開始されます。この学習が完了すると問い合わせ(分類)ができるようになりますが、完了しているかどうかを確認するには以下のコマンドを実行します:
$ node nlu status
実行結果は以下のような JSON が表示されますが、この中の status 欄が "available" となっていれば学習は完了しています。同時に表示されている model_id の値はこの後で使うので合わせてメモしておきましょう。この辺りまでは前述の NLC の時とほぼ同様ですね:
{
"status": 200,
"statusText": "OK",
"headers": {
"x-powered-by": "Express",
"content-type": "application/json; charset=utf-8",
"content-length": "401",
"etag": "W/\"191-CBnewThU0u/CjNzD01hil1wp9qo\"",
"strict-transport-security": "max-age=31536000; includeSubDomains;",
"x-dp-watson-tran-id": "15b238e1-d074-438d-8de5-44fcdfc163de",
"x-request-id": "15b238e1-d074-438d-8de5-44fcdfc163de",
"x-global-transaction-id": "15b238e1-d074-438d-8de5-44fcdfc163de",
"server": "watson-gateway",
"x-edgeconnect-midmile-rtt": "7",
"x-edgeconnect-origin-mex-latency": "228",
"date": "Tue, 24 Aug 2021 05:54:08 GMT",
"connection": "close"
},
"result": {
"models": [
{
"name": "nlc2nlu",
"user_metadata": null,
"language": "ja",
"description": null,
"model_version": "1.0.0",
"version": "1.0.0",
"workspace_id": null,
"version_description": null,
"status": "available",
"notices": [],
"model_id": "619ad785-0b0c-4981-8217-bd51064896a3",
"features": [
"classifications"
],
"created": "2021-08-24T05:43:32Z",
"last_trained": "2021-08-24T05:43:32Z",
"last_deployed": "2021-08-24T05:50:10Z"
}
]
}
}
学習が完了したら改めて日本語テキストを指定して、その内容がどのカテゴリーに属しているのかを分類してみましょう。NLC では "classify" と指定していた部分は NLU では "analyze" となる点に注意してください。日本語テキストと上述で確認した model_id 値を指定して、以下のようなコマンドを実行します:
$ node nlu analyze [日本語テキスト] [model_id]
すると以下のような結果が表示されます。指定した日本語テキストを学習データに含まれていたカテゴリー(今回作ったものだと「経済」、「IT」、「エンタメ」、「科学」、「スポーツ」)のどれに相当するものかを識別して、その可能性の高い順に結果を返しています。同じ学習データで同じ問い合わせをして、こちらでも「スポーツ」の可能性が高いと判定されていますが、その確率や2位以下の結果には違いがあることがわかります:
$ node nlu analyze パッキャオがんばれ 619ad785-0b0c-4981-8217-bd51064896a3
{
"status": 200,
"statusText": "OK",
"headers": {
"server": "watson-gateway",
"content-length": "499",
"content-type": "application/json; charset=utf-8",
"cache-control": "no-cache, no-store",
"x-dp-watson-tran-id": "93978bcf-c49e-41e9-ad00-7f0000a34e15, 93978bcf-c49e-41e9-ad00-7f0000a34e15",
"content-security-policy": "default-src 'none'",
"pragma": "no-cache",
"x-content-type-options": "nosniff",
"x-frame-options": "DENY",
"x-xss-protection": "1; mode=block",
"strict-transport-security": "max-age=31536000; includeSubDomains;",
"x-request-id": "93978bcf-c49e-41e9-ad00-7f0000a34e15",
"x-global-transaction-id": "93978bcf-c49e-41e9-ad00-7f0000a34e15",
"x-edgeconnect-midmile-rtt": "10",
"x-edgeconnect-origin-mex-latency": "354",
"date": "Tue, 24 Aug 2021 05:56:16 GMT",
"connection": "close"
},
"result": {
"usage": {
"text_units": 1,
"text_characters": 9,
"features": 1
},
"language": "ja",
"classifications": [
{
"confidence": 0.402721,
"class_name": "スポーツ"
},
{
"confidence": 0.326038,
"class_name": "経済"
},
{
"confidence": 0.314985,
"class_name": "IT"
},
{
"confidence": 0.255796,
"class_name": "エンタメ"
},
{
"confidence": 0.21978,
"class_name": "科学"
}
]
}
}
作成した学習データを IBM Watson NLU から削除するには以下のコマンドを実行します:
$ node nlu delete [model_id]
ここまでのオペレーションで NLC 同様に NLU でも「データ学習」、「学習状況確認」、「問い合わせ(分類)」、「学習データ削除」の4つを API で実現し、そのアプリケーションを実行する方法を紹介しました。とりあえず、この4つのオペレーションについては NLC から NLU へ移行することはできそうだ、という感触が持てる結果になりました。
【API レベルの移行作業】
同じオペレーションを行う NLC のツールと NLU のツールを実際に Node.js + IBM Watson SDK で開発してわかったことを記載しておきます。
まず API に互換性はありません。IAM を使った認証部分についてはほぼ同じなのですが、今回行った4つのオペレーションを実現するためのそれぞれの API は NLC のものと NLU のものは全く異なります:
| NLC の関数 | オペレーションの種類 | NLU の関数 |
|---|---|---|
| IamAuthenticator() | 認証 | IamAuthenticator() |
| createClassifier() | 分類器/モデルの作成 | createClassificationModel() |
| listClassifiers() | 作成した分類器/モデルの参照 | listClassificationModels() |
| classify() | 分類/解析 | analyze() |
| deleteClassifier() | 分類器/モデルの削除 | deleteClassificationModel() |
パラメータの指定方法など、詳しくはソースコード(nlc/nlc.js / nlu/nlu.js)を参照していただきたいのですが、大まかには上記表のような関数の違いがあります。特に Node.js + IBM Watson SDK を使っているアプリケーションにおいて NLC から NLU へ移植する場合は、表の左列にある関数を使っている箇所を右列の関数に置き換える、というのが大まかな流れになると思います(実際にはパラメータの指定方法だったり、返り値のフォーマットの違いもあったりするので、単なる文字列置換というわけにはいかないと思います)。また NLC では「分類器(Classifier)」と呼んでいたものが NLU だと「分類モデル(ClassficationModel)」と呼び名が変わっていたりもするので、資料を参照する場合の注意も必要だと思います。
加えて、上記のように NLC を使って問い合わせた結果と NLU に移植後に問い合わせた結果は必ずしも同じ結果とはいきません。このあたりの整合性についても移植の前後で意識しておく必要があります。
とはいえ、少なくとも API のレベルで NLC から NLU へアプリケーションを移植することは不可能ではなさそう、という感触も得ることができました。主要なオペレーションに関しては上述の表を使って関数を新しいものに置き換え、実行結果のフォーマットの違いをプログラミング内で吸収することができれば、ある程度の実現目途は立ちそうだと思っています。
今回の NLC のサービス終了自体は残念ではありますが、一方で見方を変えると、これまで有償サービスでしか提供されていなかった NLC の機能が、無料のライトプランで使える NLU でも利用できるようになった、とも言えます。API レベルでの互換性はありませんが、機能的には
Node.js 以外の開発言語での場合や、IBM Watson SDK の利用有無の違いをどこまで吸収できるかまでを調査したわけではないのですが、一部の言語については後述の参考資料の中でサンプルコードもあるようなので、別環境においてもぜひ挑戦していただき、情報が共有されていくことを願っています。
【参考資料】
https://cloud.ibm.com/docs/natural-language-classifier?topic=natural-language-classifier-migrating
https://cloud.ibm.com/apidocs/natural-language-understanding?code=node