連休中にふと気付いた、Bluemix / Watson デベロッパーとしては大きめのニュースです。
IBM Bluemix から提供されている Watson API 群の1つ、Text to Speech 。これは与えたテキストを自然な音声のオーディオデータにして返してくれる API サービスです。で、このサービスのカタログページ(https://console.ng.bluemix.net/catalog/text-to-speech/)をブラウザの言語設定を日本語にして参照すると、今(2015/Sep/23)も以前と特に変わらずこんな感じですが・・・

ブラウザの言語設定を英語にして同ページにアクセスすると・・・

こ、これはっ!

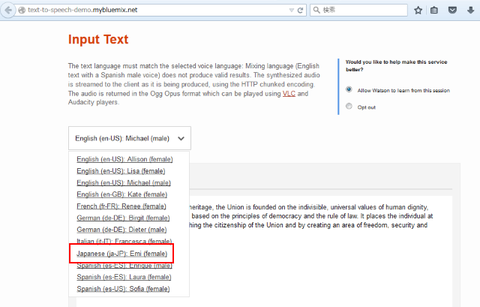
念のため、Watson Developer 向けデモページ(http://text-to-speech-demo.mybluemix.net/)を開いてみると、言語サンプルに「日本語 - エミ(女性)」なる選択肢が含まれています!!サービスがいつの間にか日本語対応していたのか!?
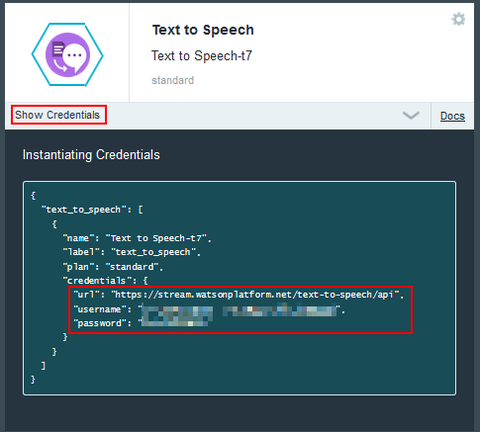
念のため、実際に API として利用できるかどうかを試してみました。Bluemix 上で Watson の Text to Speech サービスを追加し、接続情報(credentials 内の url と username と password)を参照します:
この username と password の情報を使って、ウェブブラウザ(Chrome か FireFox)で以下の URL にアクセスします:
https://(usernameの値):(passwordの値)@stream.watsonplatform.net/text-to-speech/api/v1/synthesize?voice=ja-JP_EmiVoice&text=今日はいい天気ですね
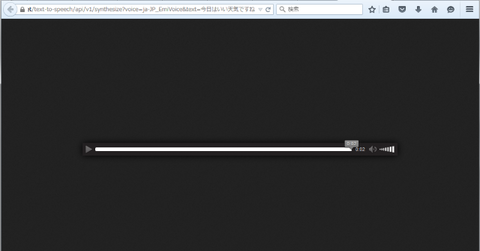
するとこんな画面になって、女性の声で「今日はいい天気ですね」と聞こえてきます。データは audio/ogg で送られてくるので、この音声フォーマットを再生することのできるブラウザを使うか、或いは受け取る側でこの音声データを再生することができれば、その場で再生されるはずです:
もちろん、これはあくまで API なので、実際のアプリケーションではそのまま再生する必要はなく、データベースに格納してもいいし、この音声データを別の API にポストしてもいいわけです。 ともあれ、いつの間にか Text to Speech が日本語対応していました!
なお、Text to Speech API のリファレンスはこちらを参照ください:
http://www.ibm.com/smarterplanet/us/en/ibmwatson/developercloud/apis/#!/text-to-speech/
で、「エミ」って誰??
IBM Bluemix から提供されている Watson API 群の1つ、Text to Speech 。これは与えたテキストを自然な音声のオーディオデータにして返してくれる API サービスです。で、このサービスのカタログページ(https://console.ng.bluemix.net/catalog/text-to-speech/)をブラウザの言語設定を日本語にして参照すると、今(2015/Sep/23)も以前と特に変わらずこんな感じですが・・・

ブラウザの言語設定を英語にして同ページにアクセスすると・・・

こ、これはっ!
念のため、Watson Developer 向けデモページ(http://text-to-speech-demo.mybluemix.net/)を開いてみると、言語サンプルに「日本語 - エミ(女性)」なる選択肢が含まれています!!サービスがいつの間にか日本語対応していたのか!?

念のため、実際に API として利用できるかどうかを試してみました。Bluemix 上で Watson の Text to Speech サービスを追加し、接続情報(credentials 内の url と username と password)を参照します:

この username と password の情報を使って、ウェブブラウザ(Chrome か FireFox)で以下の URL にアクセスします:
https://(usernameの値):(passwordの値)@stream.watsonplatform.net/text-to-speech/api/v1/synthesize?voice=ja-JP_EmiVoice&text=今日はいい天気ですね
するとこんな画面になって、女性の声で「今日はいい天気ですね」と聞こえてきます。データは audio/ogg で送られてくるので、この音声フォーマットを再生することのできるブラウザを使うか、或いは受け取る側でこの音声データを再生することができれば、その場で再生されるはずです:

もちろん、これはあくまで API なので、実際のアプリケーションではそのまま再生する必要はなく、データベースに格納してもいいし、この音声データを別の API にポストしてもいいわけです。 ともあれ、いつの間にか Text to Speech が日本語対応していました!
なお、Text to Speech API のリファレンスはこちらを参照ください:
http://www.ibm.com/smarterplanet/us/en/ibmwatson/developercloud/apis/#!/text-to-speech/
で、「エミ」って誰??