ラズベリーパイに日本語の形態素解析エンジンである MeCab をインストールする方法を紹介します。
少しだけ補足をしておくと、ただ単にラズベリーパイに MeCab をインストールするだけであれば、普通に apt-get を使って、
とかあれば導入できることは確認しました。ただこの方法で導入した MeCab を使うと、実行結果がことごとく文字化けしてしまうようでした(EUC-JP が指定されている?)。
という背景もあって、ラズパイでも文字化けせずに実行できる方法で、具体的にはソースコードからビルドする方法で MeCab を導入してみます。
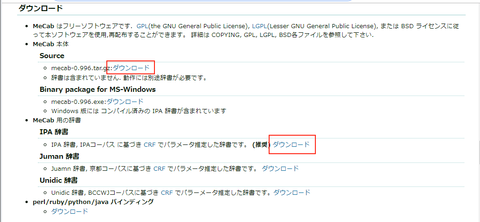
まずは MeCab のダウンロードサイトから MeCab 本体と、MeCab とセットで一般的に使われている IPA 辞書のソースコードをダウンロードし、ラズベリーパイ内のファイルシステムに保存します:
保存した2つのファイル(2019/01/23 時点では mecab-0.996.tar.gz と mecab-ipadic-2.7.0-20070801.tar.gz)を展開しておきます:
まずは MeCab 本体をビルドしてインストールします。展開したフォルダで --with-charset=utf8 オプションを付けて configure し、その後でビルド&インストールします:
次に IPA 辞書をビルド&インストールします。こちらではビルド前に各種ファイルの文字コードを無理やり UTF-8 に変換し、かつ dicrc 内の config-charset 指定を UTF-8 にします。その後にソースコードをビルド&インストールします:
この方法で作成した MeCab と IPA 辞書はラズパイでも文字化けすることなく動作させることができます:
少しだけ補足をしておくと、ただ単にラズベリーパイに MeCab をインストールするだけであれば、普通に apt-get を使って、
$ sudo apt-get install mecab libmecab-dev mecab-ipadic
とかあれば導入できることは確認しました。ただこの方法で導入した MeCab を使うと、実行結果がことごとく文字化けしてしまうようでした(EUC-JP が指定されている?)。
という背景もあって、ラズパイでも文字化けせずに実行できる方法で、具体的にはソースコードからビルドする方法で MeCab を導入してみます。
まずは MeCab のダウンロードサイトから MeCab 本体と、MeCab とセットで一般的に使われている IPA 辞書のソースコードをダウンロードし、ラズベリーパイ内のファイルシステムに保存します:

保存した2つのファイル(2019/01/23 時点では mecab-0.996.tar.gz と mecab-ipadic-2.7.0-20070801.tar.gz)を展開しておきます:
$ tar -xvf mecab-0.996.tar.gz $ tar -xvf mecab-ipadic-2.7.0-20070801.tar.gz
まずは MeCab 本体をビルドしてインストールします。展開したフォルダで --with-charset=utf8 オプションを付けて configure し、その後でビルド&インストールします:
$ cd mecab-0.996 $ ./configure --with-charset=utf8 $ make $ make check $ sudo make install $ cd ..
次に IPA 辞書をビルド&インストールします。こちらではビルド前に各種ファイルの文字コードを無理やり UTF-8 に変換し、かつ dicrc 内の config-charset 指定を UTF-8 にします。その後にソースコードをビルド&インストールします:
$ sudo apt-get install nkf $ cd mecab-ipadic-2.7.0-20070801 $ nkf -w --overwrite *.csv $ nkf -w --overwrite *.def $ vi dicrc config-charset =EUC-JPUTF-8 config-charset の値を UTF-8 に変更して保存 $ ./configure $ make $ sudo make install $ cd ..
この方法で作成した MeCab と IPA 辞書はラズパイでも文字化けすることなく動作させることができます:
$ mecab -d /usr/local/lib/mecab/dic/ipadic おはようございます おはよう 感動詞,*,*,*,*,*,おはよう,オハヨウ,オハヨー ござい 助動詞,*,*,*,五段・ラ行特殊,連用形,ござる,ゴザイ,ゴザイ ます 助動詞,*,*,*,特殊・マス,基本形,ます,マス,マス EOS