前回は dokku を使ったプライベート PaaS 環境の構築、およびシンプルなアプリケーションのデプロイ手順を紹介しました。 今回はより実践的なアプリケーションとして PostgreSQL データベースを併用するアプリケーションのデプロイ手順を紹介します(といっても、実は heroku を CLI で操作する時の手順とあまり変わりません・・)。
なお今回紹介する内容は、前回のセットアップ時に "withcorona.world" という独自ドメインを設定している想定で紹介しています。異なるドメインで設定されている場合は自分で設定したドメインに適宜読み替えてください。
【dokku 内で PostgreSQL データベースを動かす】
まず dokku 環境内にデータベースサーバーを用意します。今回は PostgreSQL を使うケースを想定して以下で紹介します。まずは dokku サーバーにログインしておきます。
dokku ではいくつかのサービスが「プラグイン」という形で連携できるよう用意されています。PostgreSQL もその1つです。というわけで、まずは dokku にログインして PostgreSQL プラグインをインストールします:
インストールが完了すると PostgreSQL データベースをインスタンス化することができるようになります。例えば "mydb" という名前を付けて1インスタンス作るには以下のように入力します:
作成後に作ったデータベースインスタンスの情報を確認する場合は以下のように入力します:
この確認結果の Dsn 値として紹介されている "postgres://" で始まる文字列がいわゆる接続文字列になっていて、(後述する)環境変数の値になります。 このインスタンスのシェルに入って PostgreSQL の CLI を使ってテーブルを1つ定義しておきたいので、以下のように実行してください(データベースに接続する時は接続文字列の "dokku-postgres-mydb" 部分を "localhost" に変えて実行してください):
これで dokku 環境内に mydb という名前の PostgreSQL データベースを1つ作り、items という名前のテーブルを1つ定義する所まで用意できました。続いて、この mydb データベースと items テーブルを使ったウェブアプリケーションを dokku 内で動かします。
【dokku 内で PostgreSQL データベースに接続するアプリケーションを動かす】
dokku 内で PostgreSQL データベースを使うアプリケーションを動かします。今回は以下のサンプルを使います(上記で作成した items テーブルを使うアプリケーションです):
https://github.com/dotnsf/cnapp_postgresql
このアプリケーションの PostgreSQL と接続する部分は以下のように記述されています:
具体的な挙動としては、アプリケーション実行時の "DATABASE_URL" という環境変数値を参照し、値が設定されていたらその内容を接続文字列とみなして PostgreSQL サーバーに接続する、という実装内容になっています(説明は省略しますが、接続後に items テーブルを読み書きする内容になっています)。
なので、このアプリケーションが dokku 内で実行される時に、先ほど作成した mydb データベースへの接続文字列が環境変数 DATABASE_URL として定義されていればこのアプリケーションは正しくデータベースに接続して動く、ということになります。
この辺りは heroku ユーザーであればなんとなく「同じだ・・」とわかると思います。で、その環境変数を設定するためには dokku 内のアプリケーションとデータベースがリンクさえされていれば実現できるようになっています(この辺りはクラウドネイティブアプリケーションを開発する際の 12 factors と呼ばれるベストプラクティスに沿った仕様となっています)。
というわけで、まずは dokku にアプリケーションを追加し、データベースとのリンクを設定します。今回は "cnapp" という名前のアプリケーションを作ることにして、この "cnapp" アプリケーションと "mydb" データベースをリンクしておきます(これで cnapp アプリの実行時にデータベース mydb に接続するための接続文字列が環境変数 DATABASE_URL にセットされて起動します):
そして前回同様にこのサンプルアプリを Git clone して、リモート接続先に dokku を追加して、main ブランチを push します:
ここまでのコマンドが正しく実行されていると http://cnapp.withcorona.world/ でアクセスできるようになります※:
※稀にこの URL では想定していないページ(Nginx のデフォルトページなど)が表示されることがあります。その場合は http://cnapp.withcorona:8080/ のようにポート番号をつけてアクセスするとうまくいきます。その後に以下のコマンドを実行するとポート番号指定なしでも正しく表示できるようになります:
これだけでも一応動きますが、ついでに(?) https 接続できるよう、Let's Encrypt プラグインの設定も行っておきます:
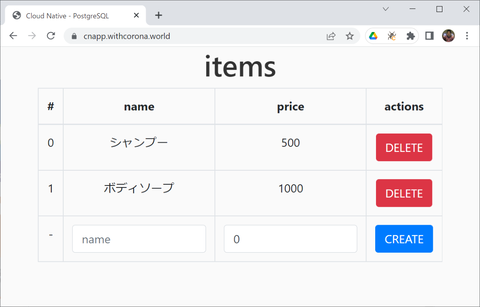
最後にウェブブラウザで https://cnapp.withcorona.world/ にアクセスして動作確認します:
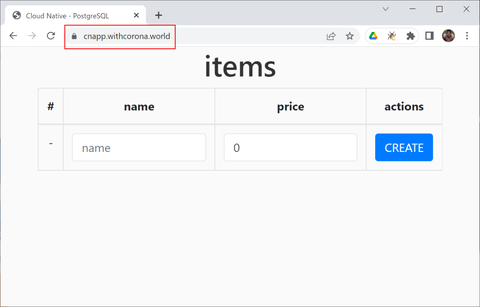
最初は何も登録されていませんが、名前(name)と価格(price)を入力して追加(Create)すると、そのデータが( PostgreSQL の)mydb データベースの items テーブルに登録され、一覧として表示されるようになります:
以上、dokku でデータベース連携アプリケーションを作って動かすための設定でした。PostgreSQL 以外にも dokku には公式機能として MySQL や Redis 、ElasticSearch といったプラグインが用意されているので、クラウドで認証した結果をセッション共有するようなアプリケーションでも動かすことができると思います。
ある程度 heroku を使ったことがある人であれば、dokku は文字通りに heroku ライクなプライベート環境に感じることができると思います(ただ dokku だとほとんどの作業が CLI からのコマンドになる点が、ウェブ GUI で色々用意されている heroku とは異なる点です)。また Cloud Foundry と比較しても、Cloud Foundry では
のようにしてアプリをデプロイしていましたが、dokku はほぼ同様にして、
といった形でアプリのデプロイができるので、Cloud Foundry の代わりとしても使いやすい環境のように感じています。今回紹介した withcorona.world というドメインは実験用の捨てドメインなのでおそらくこの紹介記事でしか使うことはないと思っていますが、他の取得ドメイン(とちょっと規模の大きめな IaaS 環境)を使って自分のプライベート Cloud Foundry 環境を作って運用してみるつもりでいます。
なお今回紹介する内容は、前回のセットアップ時に "withcorona.world" という独自ドメインを設定している想定で紹介しています。異なるドメインで設定されている場合は自分で設定したドメインに適宜読み替えてください。
【dokku 内で PostgreSQL データベースを動かす】
まず dokku 環境内にデータベースサーバーを用意します。今回は PostgreSQL を使うケースを想定して以下で紹介します。まずは dokku サーバーにログインしておきます。
dokku ではいくつかのサービスが「プラグイン」という形で連携できるよう用意されています。PostgreSQL もその1つです。というわけで、まずは dokku にログインして PostgreSQL プラグインをインストールします:
# dokku plugin:install https://github.com/dokku/dokku-postgres.git
インストールが完了すると PostgreSQL データベースをインスタンス化することができるようになります。例えば "mydb" という名前を付けて1インスタンス作るには以下のように入力します:
# dokku postgres:create mydb
作成後に作ったデータベースインスタンスの情報を確認する場合は以下のように入力します:
# dokku postgres:info mydb
=====> mydb postgres service information
Config dir: /var/lib/dokku/services/postgres/mydb/data
Config options:
Data dir: /var/lib/dokku/services/postgres/mydb/data
Dsn: postgres://postgres:XXXXXXXX@dokku-postgres-mydb:5432/mydb
Exposed ports: -
Id: a017a6896694987cb0e729b4ec1042f831eecd0d8f726d52eeea435ecd9fcf4e
Internal ip: 172.17.0.3
Links: -
Service root: /var/lib/dokku/services/postgres/mydb
Status: running
Version: postgres:14.2
この確認結果の Dsn 値として紹介されている "postgres://" で始まる文字列がいわゆる接続文字列になっていて、(後述する)環境変数の値になります。 このインスタンスのシェルに入って PostgreSQL の CLI を使ってテーブルを1つ定義しておきたいので、以下のように実行してください(データベースに接続する時は接続文字列の "dokku-postgres-mydb" 部分を "localhost" に変えて実行してください):
# dokku postgres:enter mydb (シェルにログイン) /# psql "postgres://postgres:XXXXXXXX@localhost:5432/mydb" (psql でデータベースに接続) mydb=# create table if not exists items ( id varchar(50) not null primary key, name varchar(50) default '', price int default 0, created bigint default 0, updated bigint default 0 ); (SQL で items テーブル作成) mydb=# \q (データベースから切断) /# exit (シェルからログアウト)
これで dokku 環境内に mydb という名前の PostgreSQL データベースを1つ作り、items という名前のテーブルを1つ定義する所まで用意できました。続いて、この mydb データベースと items テーブルを使ったウェブアプリケーションを dokku 内で動かします。
【dokku 内で PostgreSQL データベースに接続するアプリケーションを動かす】
dokku 内で PostgreSQL データベースを使うアプリケーションを動かします。今回は以下のサンプルを使います(上記で作成した items テーブルを使うアプリケーションです):
https://github.com/dotnsf/cnapp_postgresql
このアプリケーションの PostgreSQL と接続する部分は以下のように記述されています:
: : var database_url = 'DATABASE_URL' in process.env ? process.env.DATABASE_URL : settings.database_url; var pg = null; if( database_url ){ console.log( 'database_url = ' + database_url ); pg = new PG.Pool({ connectionString: database_url, idleTimeoutMillis: ( 3 * 86400 * 1000 ) }); : :
具体的な挙動としては、アプリケーション実行時の "DATABASE_URL" という環境変数値を参照し、値が設定されていたらその内容を接続文字列とみなして PostgreSQL サーバーに接続する、という実装内容になっています(説明は省略しますが、接続後に items テーブルを読み書きする内容になっています)。
なので、このアプリケーションが dokku 内で実行される時に、先ほど作成した mydb データベースへの接続文字列が環境変数 DATABASE_URL として定義されていればこのアプリケーションは正しくデータベースに接続して動く、ということになります。
この辺りは heroku ユーザーであればなんとなく「同じだ・・」とわかると思います。で、その環境変数を設定するためには dokku 内のアプリケーションとデータベースがリンクさえされていれば実現できるようになっています(この辺りはクラウドネイティブアプリケーションを開発する際の 12 factors と呼ばれるベストプラクティスに沿った仕様となっています)。
というわけで、まずは dokku にアプリケーションを追加し、データベースとのリンクを設定します。今回は "cnapp" という名前のアプリケーションを作ることにして、この "cnapp" アプリケーションと "mydb" データベースをリンクしておきます(これで cnapp アプリの実行時にデータベース mydb に接続するための接続文字列が環境変数 DATABASE_URL にセットされて起動します):
# dokku apps:create cnapp # dokku postgres:link mydb cnapp
そして前回同様にこのサンプルアプリを Git clone して、リモート接続先に dokku を追加して、main ブランチを push します:
# git clone https://github.com/dotnsf/cnapp_postgresql # cd cnapp_postgresql # git remote add dokku dokku@withcorona.world:cnapp # git push dokku main
ここまでのコマンドが正しく実行されていると http://cnapp.withcorona.world/ でアクセスできるようになります※:
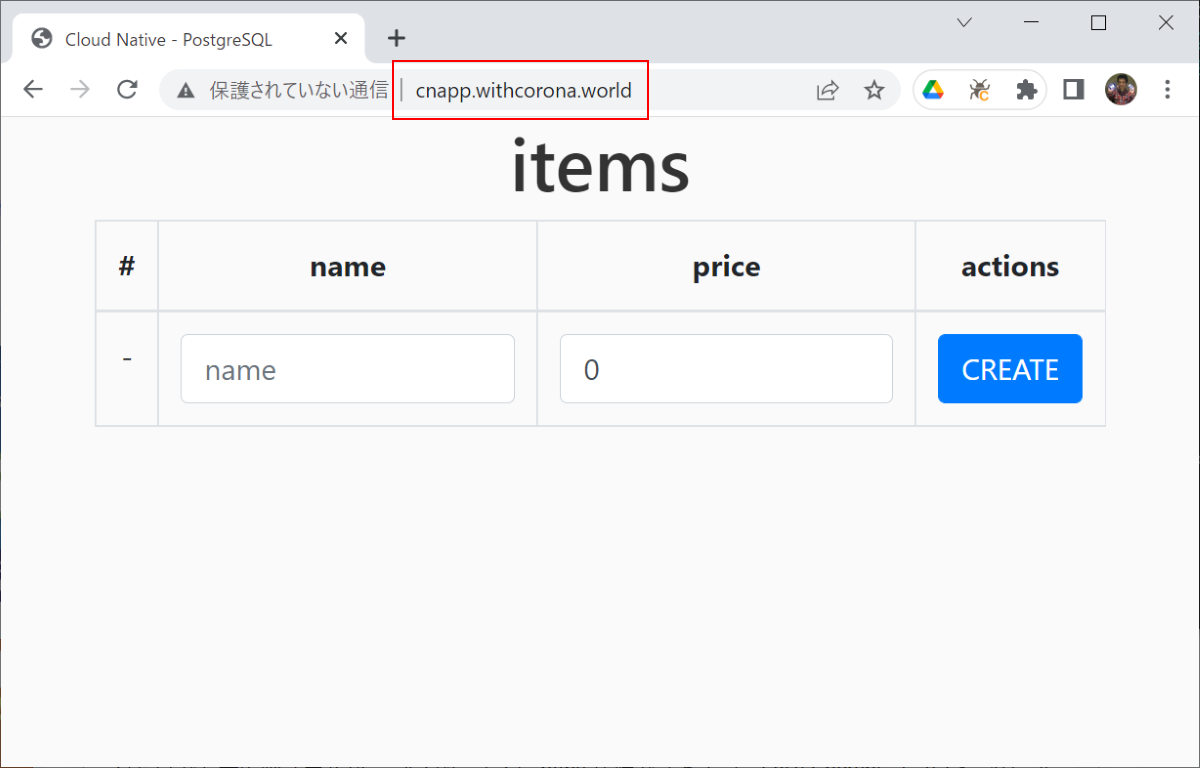
※稀にこの URL では想定していないページ(Nginx のデフォルトページなど)が表示されることがあります。その場合は http://cnapp.withcorona:8080/ のようにポート番号をつけてアクセスするとうまくいきます。その後に以下のコマンドを実行するとポート番号指定なしでも正しく表示できるようになります:
# dokku proxy:ports-add cnapp http:80:8080
これだけでも一応動きますが、ついでに(?) https 接続できるよう、Let's Encrypt プラグインの設定も行っておきます:
# dokku letsencrypt:enable cnapp
最後にウェブブラウザで https://cnapp.withcorona.world/ にアクセスして動作確認します:

最初は何も登録されていませんが、名前(name)と価格(price)を入力して追加(Create)すると、そのデータが( PostgreSQL の)mydb データベースの items テーブルに登録され、一覧として表示されるようになります:

以上、dokku でデータベース連携アプリケーションを作って動かすための設定でした。PostgreSQL 以外にも dokku には公式機能として MySQL や Redis 、ElasticSearch といったプラグインが用意されているので、クラウドで認証した結果をセッション共有するようなアプリケーションでも動かすことができると思います。
ある程度 heroku を使ったことがある人であれば、dokku は文字通りに heroku ライクなプライベート環境に感じることができると思います(ただ dokku だとほとんどの作業が CLI からのコマンドになる点が、ウェブ GUI で色々用意されている heroku とは異なる点です)。また Cloud Foundry と比較しても、Cloud Foundry では
$ cf push (app)
のようにしてアプリをデプロイしていましたが、dokku はほぼ同様にして、
$ git remote add dokku (app) (を一度実行してから)
$ git push dokku main
といった形でアプリのデプロイができるので、Cloud Foundry の代わりとしても使いやすい環境のように感じています。今回紹介した withcorona.world というドメインは実験用の捨てドメインなのでおそらくこの紹介記事でしか使うことはないと思っていますが、他の取得ドメイン(とちょっと規模の大きめな IaaS 環境)を使って自分のプライベート Cloud Foundry 環境を作って運用してみるつもりでいます。