久しぶりにウェブサービスを作ってみたので、紹介含めてブログにまとめました。アイデアそのものは2週間ほど前に思いついて脳内設計し、1週間くらい前から作ったり改良を加えたりして、この三連休でとりあえず公開できるレベルになったかな、という感じです。
作ったのはいわゆる CMS (=Contents Management System「コンテンツ管理システム」)です。特徴的な要素として GitHub Issues を使っている、という点が挙げられると思っています。要は CMS のコンテンツそのものは専用 DB などに格納するのではなく、GitHub のリポジトリ内のプロジェクト/課題管理ツールである GitHub Issues を使っています。多くのケースでは GitHub Issues はプロジェクトの課題を記録したり、課題をカテゴリーに分類したり、課題の担当者や解決目標時期を割り当てたり、スレッド形式のコメントを追加したりしながら、プロジェクト全体の進捗を管理することに使われることが多いと思いっています。一方で、この GitHub Issues の仕組み自体はプロジェクト管理だけに使うのはもったいないほど色んな機能が無料で提供されているとも考えることができます。今回作成した GHaC(GitHub as CMS)は GitHub API を使って GitHub のログインや GitHub Issues の取得を行い、CMS 寄りの UI で表示することで CMS として使ってみたら面白いのでは? という興味から生まれたものです。
なお、2022/10/10 の現時点では PC 向けの UI のみ提供しています。
【GHaC の使い方】
GHaC を使う場合はまずウェブブラウザで以下にアクセスします:
https://ghac.me/
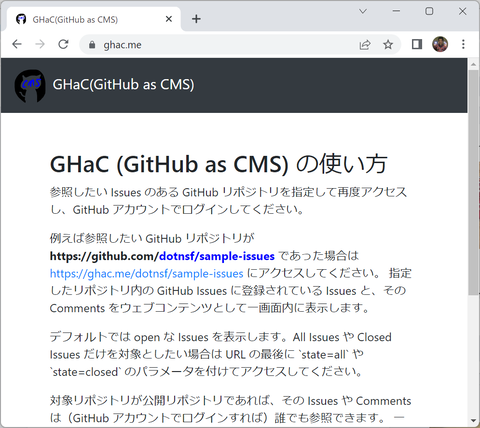
GHaC の紹介と簡単な使い方が説明されています。以下、このページに書かれた内容と重複する箇所がありますが、こちらでも使い方を説明します。
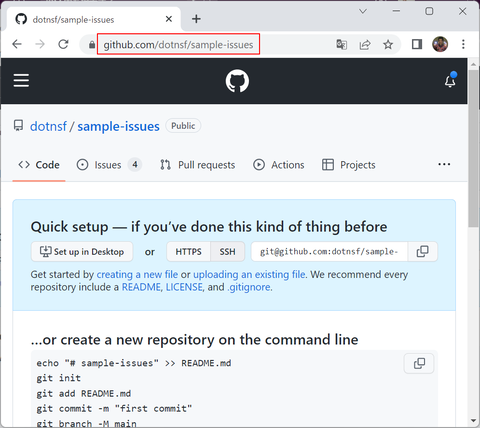
GHaC は GitHub のリポジトリを参照して(そのリポジトリの Issues や Comments を取り出して)コンテンツを表示します。例えばサンプルとして dotnsf/sample-issues という公開リポジトリを見る場合を想定します。なお、このリポジトリはソースコードとしては何もコミットされていないので、リポジトリを直接参照すると初期状態のまま表示されます:
(https://github.com/dotnsf/sample-issues の画面)
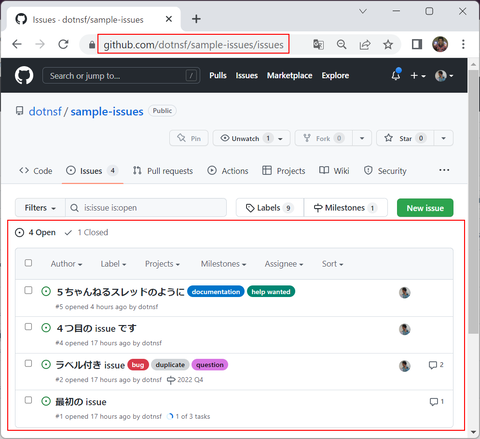
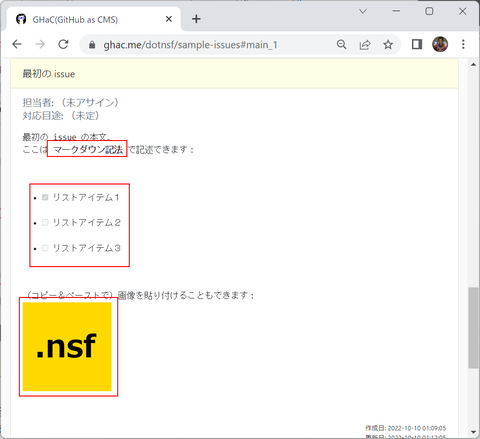
ソースコードは空ですが、GitHub Issues としての情報はいくつかの Issues と、各 Issue にコメントがついていたり、いなかったりします:
(https://github.com/dotnsf/sample-issues/issues の画面。4つの Open な Issues と、表示されていない1つの Closed Issue が登録されています。また Comments が付与されている Issues は右側に吹き出しマークと一緒に Comments の数が表示されています)
GHaC でこのリポジトリを参照する場合は https://ghac.me/ に続けて対象リポジトリを追加した URL にアクセスします。このリポジトリ(dotnsf/sample-issues)の場合であれば https://ghac.me/dotnsf/sample-issues にアクセスします。以下のような画面になります:
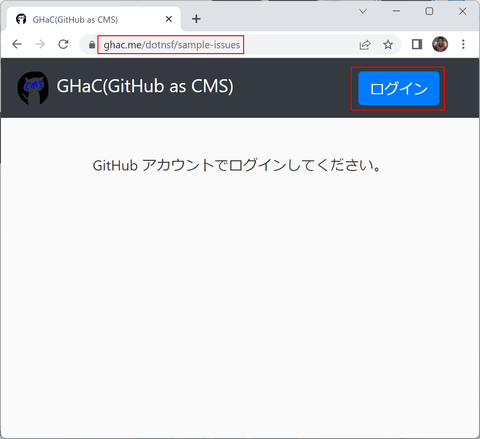
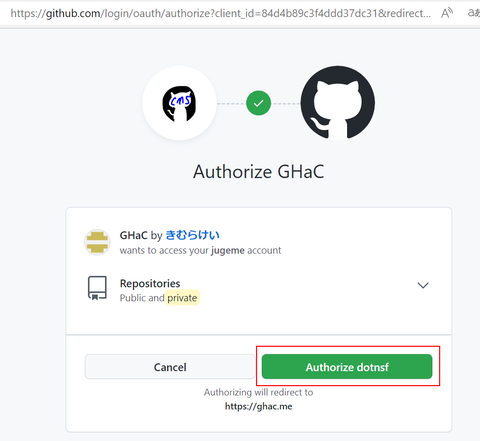
最初は認証されていない状態でアクセスすることになるので上記のようなログインを促すメッセージだけが表示されています。画面右上の「ログイン」ボタンで GitHub の OAuth 認証ページに移動し、GitHub アカウントを指定してログインします。初回のみ以下のような画面になるので右下緑の "Authorize dotnsf" ボタンをクリックしてください:
ログインが成功すると以下のような画面に切り替わります。なお、このリポジトリの例(dotnsf/sample-issues)は公開リポジトリなので誰がログインしてもこのように表示されますが、非公開リポジトリの場合はログインしたユーザーの参照権限の可否によって表示されたり、されなかったりします:
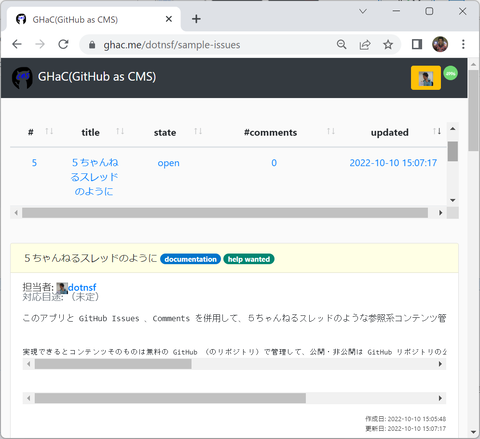
画面最上部右にはログインしたユーザーの(GitHub の)プロフィールアイコンが表示されます。このアイコンをクリックすると GitHub からログアウトして GHaC のトップページに戻ります。またその右には GitHub API を実行できる回数※の目安が円グラフで表示されています。このグラフ部分にマウスのカーソルを重ねると、リセットまでの残り API 実行回数と、次回リセットの日付時刻が表示されます:
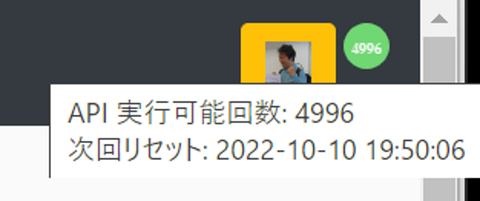
※
GitHub API は1時間で 5000 回実行できます。1つのリポジトリの Issues や Comments を取得するために実行する API の回数はリポジトリによって異なります。↑の例ではこのページを表示するために既に4回実行していて、2022/10/10 19:50:06 までにあと 4996 回実行できる、という内容が表示されています(2022/10/10 19:50:06 になると API 実行はリセットされて、新たに 5000 回利用できるようになります)。
また画面上部には指定したリポジトリ内の open な issues がテーブル形式で表示されています:
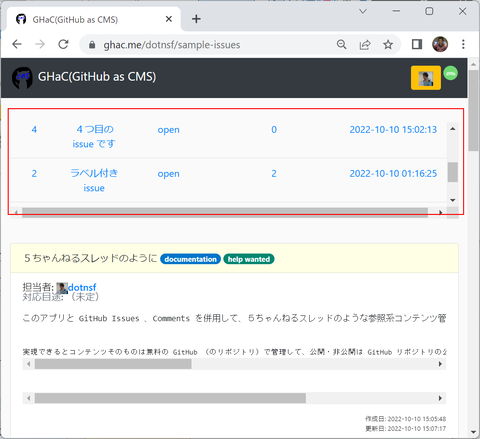
(参考 もとのリポジトリの Issues の同じ該当部分)
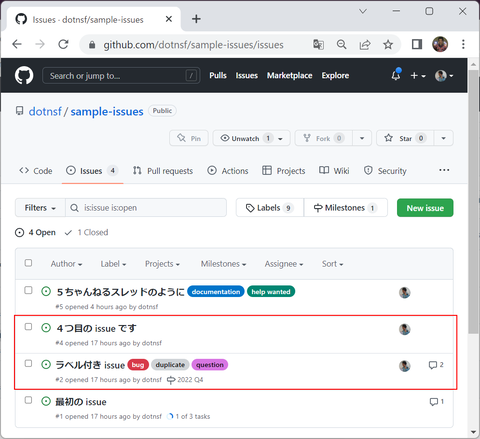
画面下部には各 Issues と、その Issue に Comments がついている場合は全ての Comments がスレッド形式で表示されています。画面をスクロールすれば全て見ることができますが、特定の Issue の内容を確認したい場合は上部テーブルの該当 Issue をクリックすると、その Issue のスレッドに移動します。
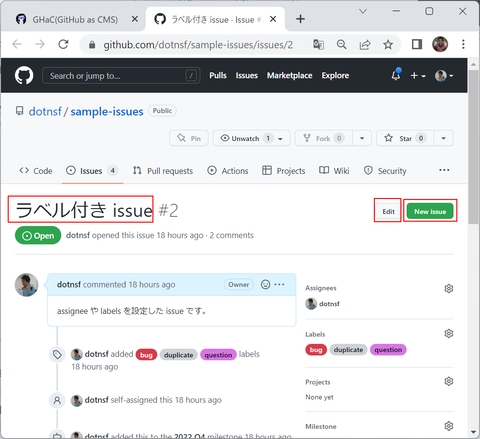
例えば「ラベル付き issue」(Comments 数は2)と書かれたこの部分をクリックすると、
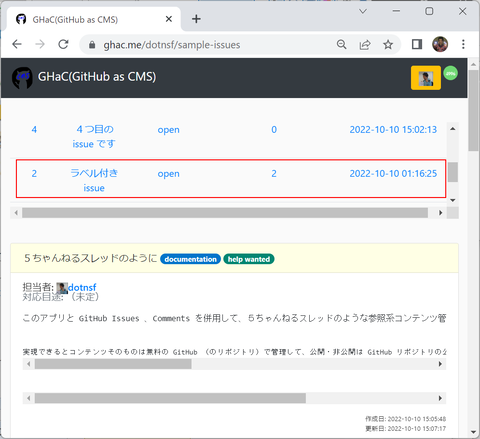
該当 Issue が表示されている箇所までスクロールして表示することができます:
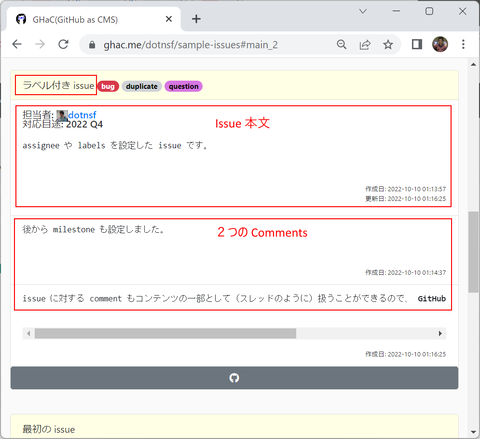
Issue 本文や Comments 内容はマークダウン記法で記述されており、GHaC でも同様に表示されます(mermaid 記法には対応していません)。マークダウンによるリッチテキストを含む Issues や Comments はリッチテキストが再現されて表示されます:
(2022/10/13 追記)
mermaid 記法と MathJax 記法に対応しました。
また現時点では GHaC は参照専用のツールです。GitHub リポジトリ内の Issues や Comments を編集するにはこのリポジトリを編集する権限をもったユーザーでログインした後に、画面内の GitHub アイコン(オクトキャットアイコン)をクリックすると・・
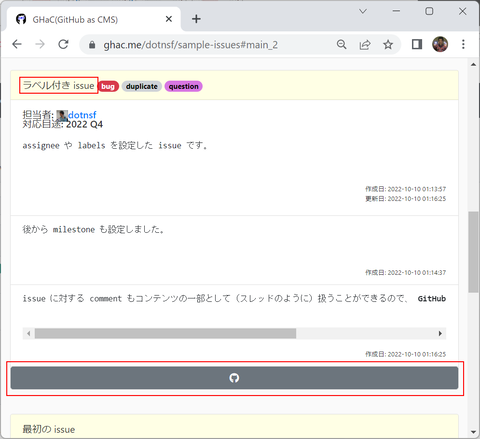
対象リポジトリの対象 Issue の GitHub 画面が別タブで表示されます。必要に応じて、この画面から Edit ボタンをクリックして内容を編集したり、Comments を追加したり、New issue ボタンから新しい Issue を追加してください(保存後に GHaC 画面をリロードすればすぐに反映されているはずです)。余談ですが GitHub Issues の編集画面はマークダウンで記述できるだけでなく、OS からのコピー&ペーストで画像を貼りつけることができるので、リッチテキストの編集がとても楽です:
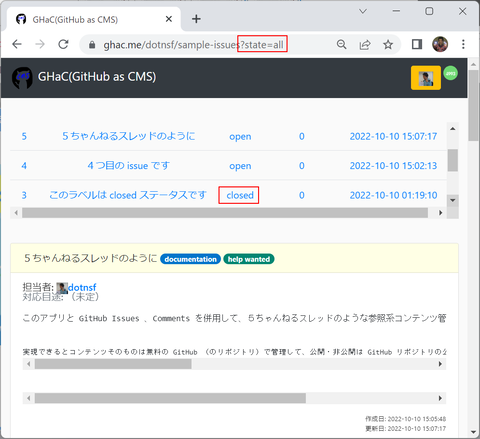
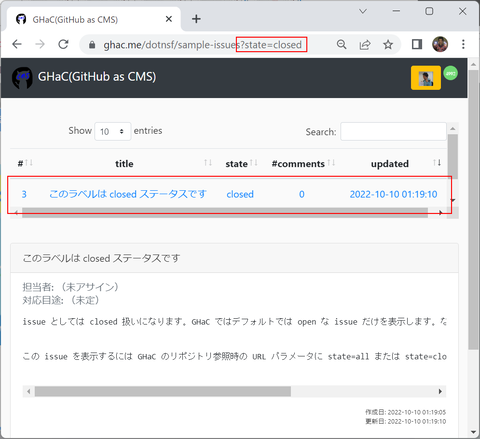
なお、GHaC はデフォルトでは指定されたリポジトリの Open な Issues だけを対象にこのような画面を提供します。全ての Issues やクローズされた Issues だけを対象としたい場合は URL の最後にそれぞれ state=all (全ての Issues)や state=close (クローズされた Issues)というパラメータを付けてアクセスすることで目的の Issues を変更することができます(実はこれ以外にも URL パラメータで対象 Issues を絞り込むことができるようにしていますが、GitHub API でのオプションと同じ仕様にしているので興味ある人は自分で調べてみてください):
【まとめ】
このように GitHub Issues をウェブコンテンツのように使うことができるようになるのが GHaC の魅力です。GitHub Issues 本来の使い方とは異なるので少し慣れが必要かもしれませんが、ある意味で GitHub を無料のデータ管理ができるヘッドレス CMS のように使うことができると思っています。
なおこの GHaC を使うことで、公開されている全ての GitHub リポジトリを対象にこのような UI で Issues や Comments を表示することができるようになります。ただ例えば node-red/node-red のような Issues が多く登録されているようなリポジトリに対して実行すると1回の表示に必要な API 実行回数も多くなり、結果として表示されるまでにかかる時間も長くなってしまいます。その点に注意の上でリポジトリを指定して実行してください:
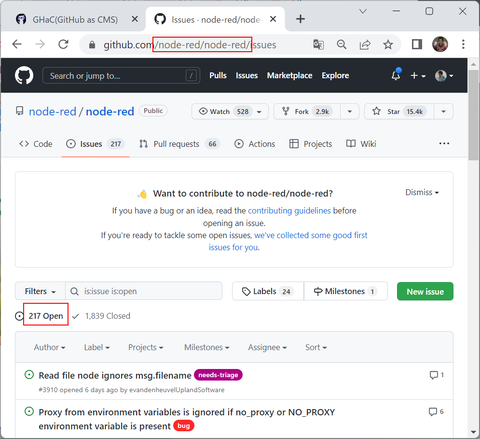
(表示まで1分近くかかりました・・)
まだまだ不具合も見つかっており、今後はその対処が必要になることに加え、現在は Oracle Cloud の無料インスタンス1つを使って運用していることもあって決して潤沢なサーバー環境ではありません。いろいろ不便があるかもしれませんが、ある程度理解した上で(主に情報提供用の)コンテンツ公開サービスと考えると、アクセス権管理も含めて結構使い道あるサービスなのではないかと思っています。
しばらく今の形で公開するつもりなので是非いろいろ使っていただき、ご意見やご要望などあれば伺って今後のサービス向上に役立てていきたいと思っています。
作ったのはいわゆる CMS (=Contents Management System「コンテンツ管理システム」)です。特徴的な要素として GitHub Issues を使っている、という点が挙げられると思っています。要は CMS のコンテンツそのものは専用 DB などに格納するのではなく、GitHub のリポジトリ内のプロジェクト/課題管理ツールである GitHub Issues を使っています。多くのケースでは GitHub Issues はプロジェクトの課題を記録したり、課題をカテゴリーに分類したり、課題の担当者や解決目標時期を割り当てたり、スレッド形式のコメントを追加したりしながら、プロジェクト全体の進捗を管理することに使われることが多いと思いっています。一方で、この GitHub Issues の仕組み自体はプロジェクト管理だけに使うのはもったいないほど色んな機能が無料で提供されているとも考えることができます。今回作成した GHaC(GitHub as CMS)は GitHub API を使って GitHub のログインや GitHub Issues の取得を行い、CMS 寄りの UI で表示することで CMS として使ってみたら面白いのでは? という興味から生まれたものです。
なお、2022/10/10 の現時点では PC 向けの UI のみ提供しています。
【GHaC の使い方】
GHaC を使う場合はまずウェブブラウザで以下にアクセスします:
https://ghac.me/
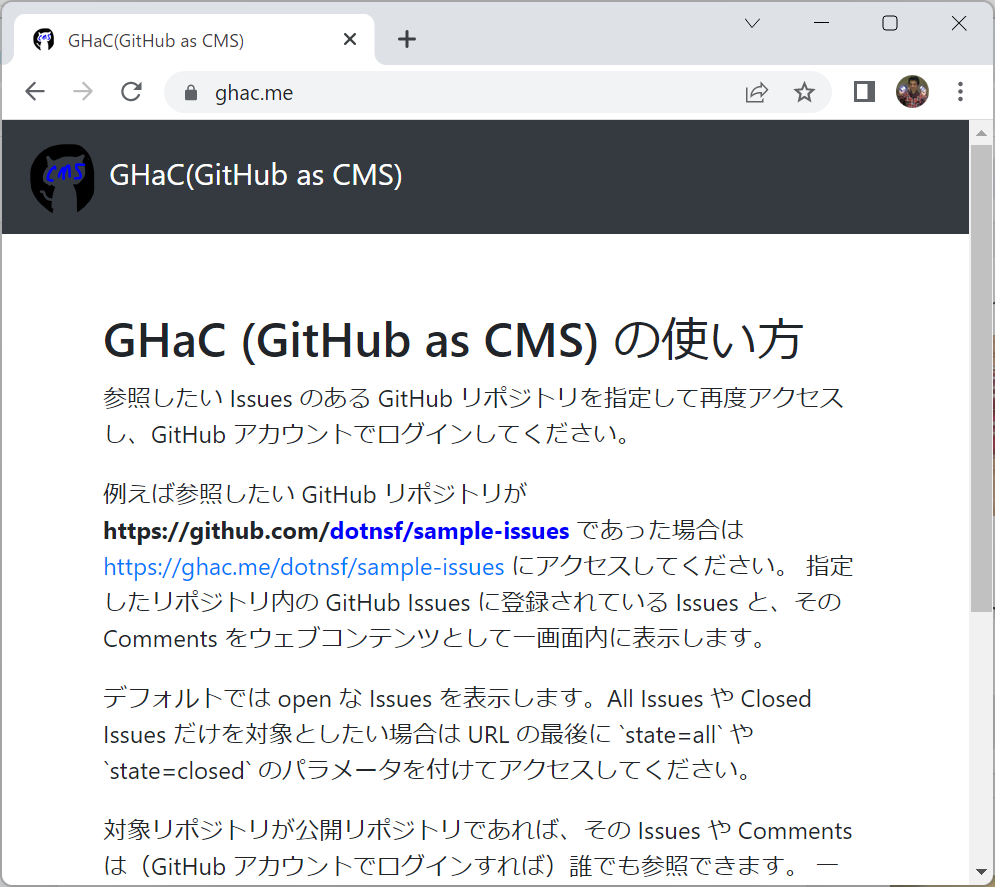
GHaC の紹介と簡単な使い方が説明されています。以下、このページに書かれた内容と重複する箇所がありますが、こちらでも使い方を説明します。
GHaC は GitHub のリポジトリを参照して(そのリポジトリの Issues や Comments を取り出して)コンテンツを表示します。例えばサンプルとして dotnsf/sample-issues という公開リポジトリを見る場合を想定します。なお、このリポジトリはソースコードとしては何もコミットされていないので、リポジトリを直接参照すると初期状態のまま表示されます:
(https://github.com/dotnsf/sample-issues の画面)

ソースコードは空ですが、GitHub Issues としての情報はいくつかの Issues と、各 Issue にコメントがついていたり、いなかったりします:
(https://github.com/dotnsf/sample-issues/issues の画面。4つの Open な Issues と、表示されていない1つの Closed Issue が登録されています。また Comments が付与されている Issues は右側に吹き出しマークと一緒に Comments の数が表示されています)

GHaC でこのリポジトリを参照する場合は https://ghac.me/ に続けて対象リポジトリを追加した URL にアクセスします。このリポジトリ(dotnsf/sample-issues)の場合であれば https://ghac.me/dotnsf/sample-issues にアクセスします。以下のような画面になります:

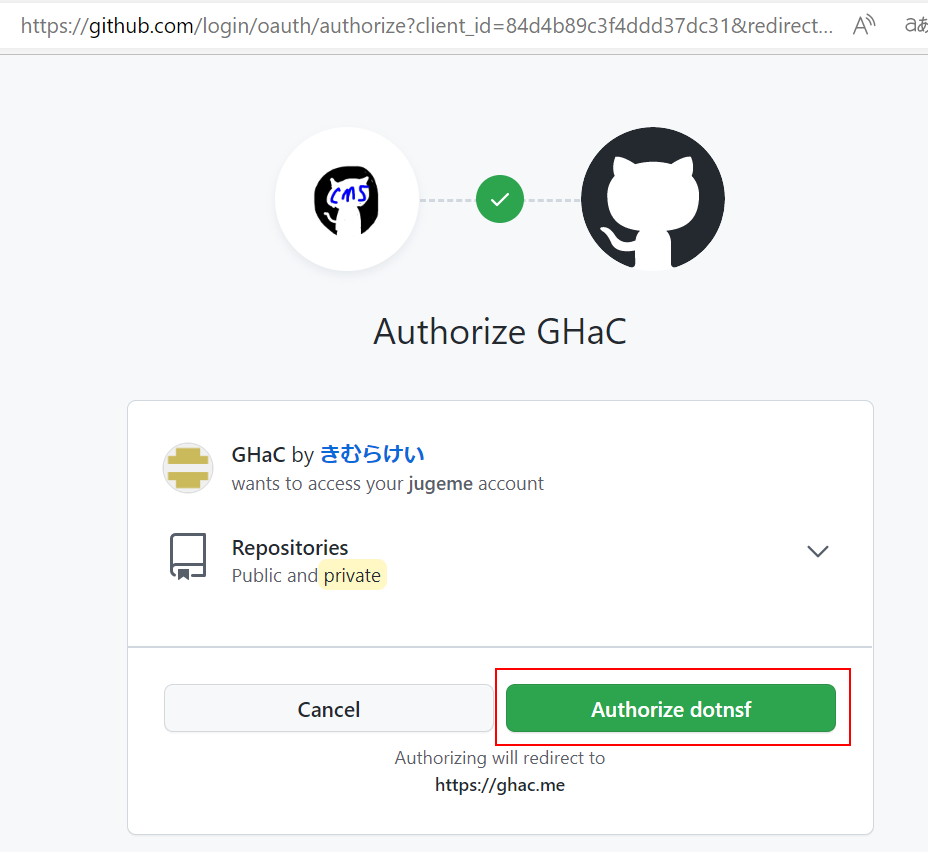
最初は認証されていない状態でアクセスすることになるので上記のようなログインを促すメッセージだけが表示されています。画面右上の「ログイン」ボタンで GitHub の OAuth 認証ページに移動し、GitHub アカウントを指定してログインします。初回のみ以下のような画面になるので右下緑の "Authorize dotnsf" ボタンをクリックしてください:
ログインが成功すると以下のような画面に切り替わります。なお、このリポジトリの例(dotnsf/sample-issues)は公開リポジトリなので誰がログインしてもこのように表示されますが、非公開リポジトリの場合はログインしたユーザーの参照権限の可否によって表示されたり、されなかったりします:

画面最上部右にはログインしたユーザーの(GitHub の)プロフィールアイコンが表示されます。このアイコンをクリックすると GitHub からログアウトして GHaC のトップページに戻ります。またその右には GitHub API を実行できる回数※の目安が円グラフで表示されています。このグラフ部分にマウスのカーソルを重ねると、リセットまでの残り API 実行回数と、次回リセットの日付時刻が表示されます:

※
GitHub API は1時間で 5000 回実行できます。1つのリポジトリの Issues や Comments を取得するために実行する API の回数はリポジトリによって異なります。↑の例ではこのページを表示するために既に4回実行していて、2022/10/10 19:50:06 までにあと 4996 回実行できる、という内容が表示されています(2022/10/10 19:50:06 になると API 実行はリセットされて、新たに 5000 回利用できるようになります)。
また画面上部には指定したリポジトリ内の open な issues がテーブル形式で表示されています:

(参考 もとのリポジトリの Issues の同じ該当部分)

画面下部には各 Issues と、その Issue に Comments がついている場合は全ての Comments がスレッド形式で表示されています。画面をスクロールすれば全て見ることができますが、特定の Issue の内容を確認したい場合は上部テーブルの該当 Issue をクリックすると、その Issue のスレッドに移動します。
例えば「ラベル付き issue」(Comments 数は2)と書かれたこの部分をクリックすると、

該当 Issue が表示されている箇所までスクロールして表示することができます:
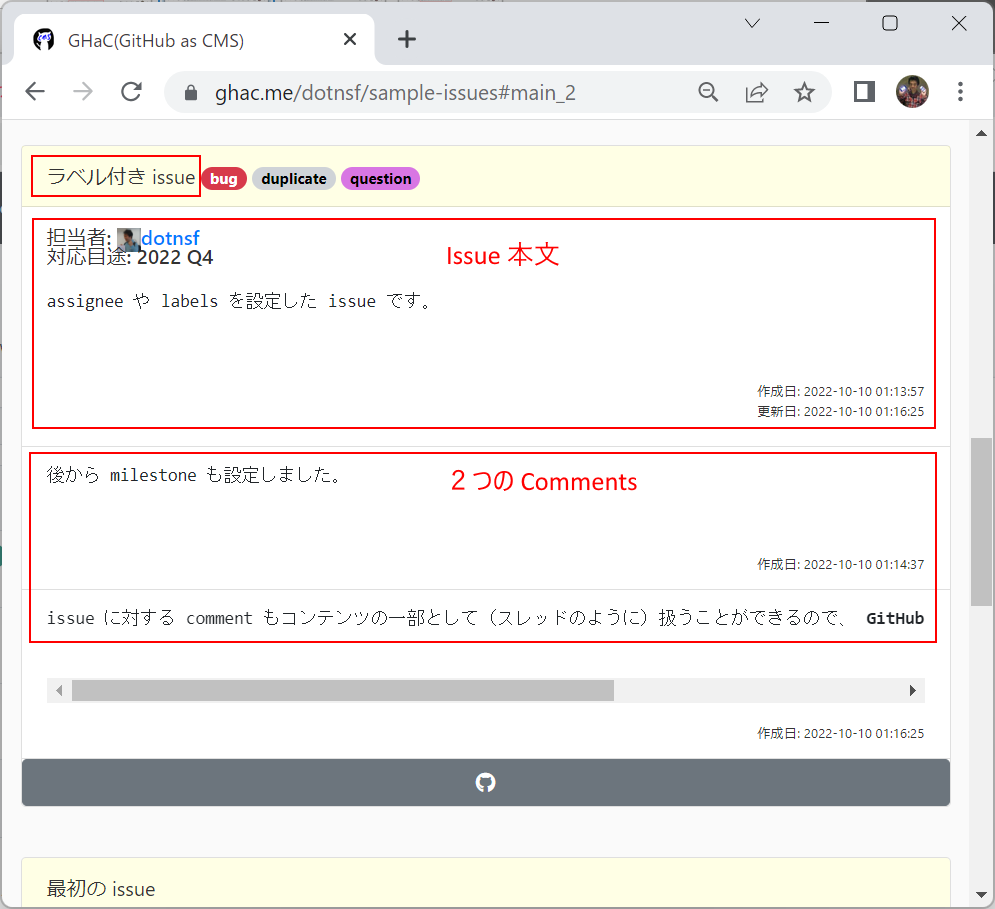
Issue 本文や Comments 内容はマークダウン記法で記述されており、GHaC でも同様に表示されます(mermaid 記法には対応していません)。マークダウンによるリッチテキストを含む Issues や Comments はリッチテキストが再現されて表示されます:

(2022/10/13 追記)
mermaid 記法と MathJax 記法に対応しました。
また現時点では GHaC は参照専用のツールです。GitHub リポジトリ内の Issues や Comments を編集するにはこのリポジトリを編集する権限をもったユーザーでログインした後に、画面内の GitHub アイコン(オクトキャットアイコン)をクリックすると・・

対象リポジトリの対象 Issue の GitHub 画面が別タブで表示されます。必要に応じて、この画面から Edit ボタンをクリックして内容を編集したり、Comments を追加したり、New issue ボタンから新しい Issue を追加してください(保存後に GHaC 画面をリロードすればすぐに反映されているはずです)。余談ですが GitHub Issues の編集画面はマークダウンで記述できるだけでなく、OS からのコピー&ペーストで画像を貼りつけることができるので、リッチテキストの編集がとても楽です:

なお、GHaC はデフォルトでは指定されたリポジトリの Open な Issues だけを対象にこのような画面を提供します。全ての Issues やクローズされた Issues だけを対象としたい場合は URL の最後にそれぞれ state=all (全ての Issues)や state=close (クローズされた Issues)というパラメータを付けてアクセスすることで目的の Issues を変更することができます(実はこれ以外にも URL パラメータで対象 Issues を絞り込むことができるようにしていますが、GitHub API でのオプションと同じ仕様にしているので興味ある人は自分で調べてみてください):


【まとめ】
このように GitHub Issues をウェブコンテンツのように使うことができるようになるのが GHaC の魅力です。GitHub Issues 本来の使い方とは異なるので少し慣れが必要かもしれませんが、ある意味で GitHub を無料のデータ管理ができるヘッドレス CMS のように使うことができると思っています。
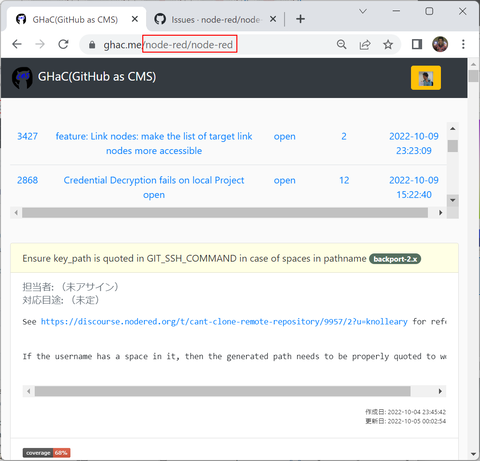
なおこの GHaC を使うことで、公開されている全ての GitHub リポジトリを対象にこのような UI で Issues や Comments を表示することができるようになります。ただ例えば node-red/node-red のような Issues が多く登録されているようなリポジトリに対して実行すると1回の表示に必要な API 実行回数も多くなり、結果として表示されるまでにかかる時間も長くなってしまいます。その点に注意の上でリポジトリを指定して実行してください:

(表示まで1分近くかかりました・・)

まだまだ不具合も見つかっており、今後はその対処が必要になることに加え、現在は Oracle Cloud の無料インスタンス1つを使って運用していることもあって決して潤沢なサーバー環境ではありません。いろいろ不便があるかもしれませんが、ある程度理解した上で(主に情報提供用の)コンテンツ公開サービスと考えると、アクセス権管理も含めて結構使い道あるサービスなのではないかと思っています。
しばらく今の形で公開するつもりなので是非いろいろ使っていただき、ご意見やご要望などあれば伺って今後のサービス向上に役立てていきたいと思っています。