IBM Cloud から提供されている Db2 on Cloud を、2021/05/23 時点では最新となる v4 API を使ってアクセスするまでを実現した Node.js のサンプルアプリケーションを作りました。アクセストークンを取得して SQL を実行し、その結果を取得するまでの一連の流れを紹介します。
Db2 on Cloud は IBM 製リレーショナルデータベース製品である Db2 をマネージドサービスとして IBM Cloud から提供しているサービスです。IBM Cloud のライトアカウントを作成し、フリープランを選択することで、データは 200MB までなどの制約はありますが無料で利用することも可能です:
この Db2 は製品としての経緯もあり、専用(ネイティブ)クライアントライブラリをインストールした上で JDBC/ODBC などから利用することが多かったのですが、近年は Node.js 向けのライブラリなども提供されるようになり、各種プログラミング言語からの利用もできるようになっていました。その API の最新版(v4)では REST API 対応が行われ、(ラズベリーパイなど)専用クライアントライブラリが存在しなかった環境からの利用も可能になりました。
というわけで、今回のブログエントリではこの v4 API を使って Db2 on Cloud のインスタンスにアクセスして SQL を実行し、その実行結果を取得するまでの一連の手順をサンプルアプリケーションとそのコードを参照しつつ紹介します。
【サンプルアプリケーション】
以下で紹介するサンプルアプリケーションの(Node.js 向け)ソースコードはこちらで公開しています:
https://github.com/dotnsf/node-db2
Node.js がインストールされていれば Windows でも Mac でも Linux でも動きます。特にこのアプリケーションは v4 API で作っているので、これまでは(クライアントライブラリが提供されていないため)Db2 にアクセスできなかったラズベリーパイなどの環境からでも利用できる点が特徴になっています。なのでラズパイ環境をお持ちだったらぜひラズパイから利用してみていただきたいです。
サンプルアプリを利用するには、まず IBM Cloud 側の準備が必要です。大まかに以下2段階の準備を行います:
(1)IBM Cloud にログインして Db2 on Cloud サービスインスタンスを作成
(2)作成したインスタンスの接続情報を取得
まず(1)を行います。IBM Cloud に(必要であればアカウントを作成して)ログインし、Db2 サービスインスタンスを作成します:
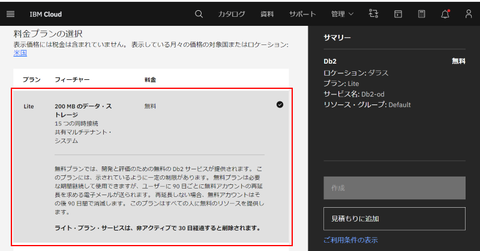
この際に "Lite" プランを選択しておくとデータ量 200MB 上限や、同時接続数 15 などの制約がありますが、無料で利用することができます:
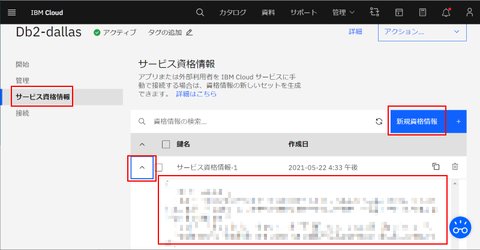
(1)のインスタンスを作成したら(2)の準備を行います。作成したインスタンスの「サービス資格情報」タブを選択し、「新規資格情報」ボタンで「サービス資格情報」を1つ追加して、その中身を確認します:
以下のような JSON フォーマットの情報を確認することができます:
ここで必要になるのは以下の3つの値です:
・username
・password
・hostname
加えて deployment id を取得します。この ID はサービス固有の ID で、すべての REST API 実行時に必要な値です。取得方法はサービスを表示しているブラウザ画面の URL を確認します:
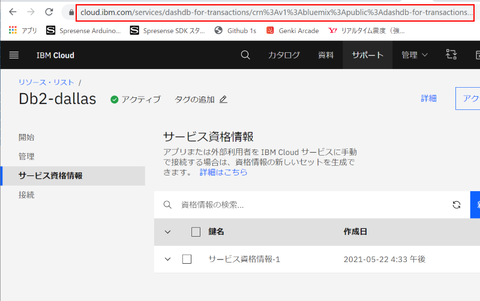
おそらくこのようなフォーマットの URL 文字列になっています:
この中の "crn" で始まる文字列(? が含まれる場合はその手前まで)を URL デコードした値が deployment id です。URL デコードといってもパターンは2つに決まっていて、"%3A" を ":" に、"%2F" を "/" に変換するだけです。例えば該当の Db2 on Cloud サービスを表示している時の URL 内文字列がこの内容だった場合、
deployment id は crn で始まる青字部分を URL デコードした値ということになり、具体的には以下の値となります:
以上、ここまでの作業で Db2 on Cloud のサービスインスタンスを作成し、その username, password, hostname, deployment id の4つの情報を取得することができました。この4つの値が取得できれば、実際にサンプルアプリケーションを動かすことができます。
上述のリポジトリ URL から git clone やダウンロード&展開するなどしてソースコード一式を取得します。そして settings.js をテキストエディタで開いて、先程取得した4つの値を入力して保存します:
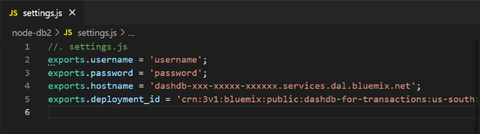
これでソースコード側に必要な変更も完了です。では実際に Node.js で動かしてみましょう:
ここまでのコマンドを実行すると、サンプルのウェブアプリケーションは 8080 番ポートで待ち受ける形で起動します。ウェブブラウザ(別 PC からでも可)からサンプルの HTTP リクエストを送信して、Db2 on Cloud で SQL を実行し、その結果を取得します:
なお、この GET /ping リクエストは Db2 on Cloud インスタンスに対して以下の SQL を実行した結果のシステム情報を取得するように作られたものです:
実際にウェブブラウザでこの URL にアクセスするとこのような結果になります。上述の SQL を実行した結果が JSON で返ってきました。仮にアプリケーションをラズベリーパイ上で動かしていても同様の結果が取得できているはずです。これまでは Db2 のクライアントライブラリが導入できる環境からでないと実行できなかった SQL を、v4 API では(サーバー上のもの以外には)クライアントライブラリを使わない環境でも実行して結果を取得することができる、ということがわかります:

【ソースコード解説】
ではソースコードを見ながら v4 API の解説をします。上述のオペレーションで使っているファイルは変数設定以外は app.js のみなので、全容を確認したい場合はこのファイルを参照ください。
上述で行ったのは1つの SQL を実行して、その結果を取得する、というごく普通のオペレーションですが、v4 API では大きく3つのパートに分かれて処理されています((2)と(3)が別れて処理されている点に注目):
(1)アクセストークン取得
(2)SQL 実行
(3)SQL 結果取得
まず(1)について。これまでの Db2 API では認証時にユーザー名とパスワードがあればログインして SQL を実行することができましたが、v4 API では(今どきらしく)まずアクセストークンを取得して、アクセストークンを付与しながら SQL を実行する必要があります。というわけでアクセストークンの取得手順を紹介します。
具体的には以下のようなコードを実行しているのですが、settings.js に設定した username と password を https://(hostname)/dbapi/v4/auth/tokens に POST しています。またその際の HTTP リクエストヘッダ内で deployment id の値を送付しています(HTTP リクエストヘッダに deployment id を含める、というのは以下すべての REST API で共通です)。成功した場合、返されるオブジェクトの token キーにアクセストークンが付与されて返ってくるので、この値を保存しています(実際のアプリではセッション等に保存しておくべきです):
GET /ping にリクエストがあると、このアクセストークンを使って(2)SQL を実行します。app.js では以下のように実行しています:
GET /ping リクエストへのハンドラとして、まず "select TABNAME, TABSCHEMA, OWNER from syscat.tables fetch first 5 rows only;" という SQL を https://(hostname)/dbapi/v4/sql_jobs に POST して実行しています。この処理が成功すると、返されるオブジェクトに id というキー値が含まれています。
そして(3)では、実行した SQL の結果を取得します。その際には(2)で取得した id キー値を指定して GET https://(hostname)/dbapi/v4/sql_jobs/(id) を実行して、その結果が先程のブラウザ画面のようなフォーマットで取得されていたのでした:
NoSQL とは違って、トランザクションを含む(時間のかかる)処理を実行する可能性もあるため、その間で処理をブロックしないようにこのような仕様で API が用意されているのだと思います。上の例では SQL の実行と結果の取得を続けて行って実行結果を返していますが、(途中に取得できる id をいったんクライアントに返すことで)これら2つの処理を別の REST API で分けて実行させることも可能になります。シングルスレッドの Node.js での実装を考慮すると、こちらのほうがより正しいといえるかもしれません。
【良い点・悪い点】
なんといっても「ラズベリーパイなどの、Db2 クライアントライブラリが提供されていないシステムから Db2 サーバーに接続してクエリーを実行できる」ようになったことが大きな改善点であると感じました。また時間のかかる処理を実行する際にも、まとめて実行して、その間の他のリクエストをブロックすることなく、後から結果を確認できるようになっている点もクラウド時代らしいといえます。
唯一残念な点は「プレースホルダー型の SQL に未対応」な点です。SQL を比較的安全に実行する上でよく使われるプレースホルダー型の SQL("SELECT * from xxxxx where id = ?" で、パラメーターの id を分けて送って実行する SQL)には現時点ではこの REST API では未対応のようで、現時点では開発者が気をつけて実装するか、(クライアントライブラリが提供されているシステムから)従来の専用ライブラリを使って実行する必要がありそうでした。
【参考】
IBM Db2 on Cloud REST API
Db2 on Cloud は IBM 製リレーショナルデータベース製品である Db2 をマネージドサービスとして IBM Cloud から提供しているサービスです。IBM Cloud のライトアカウントを作成し、フリープランを選択することで、データは 200MB までなどの制約はありますが無料で利用することも可能です:

この Db2 は製品としての経緯もあり、専用(ネイティブ)クライアントライブラリをインストールした上で JDBC/ODBC などから利用することが多かったのですが、近年は Node.js 向けのライブラリなども提供されるようになり、各種プログラミング言語からの利用もできるようになっていました。その API の最新版(v4)では REST API 対応が行われ、(ラズベリーパイなど)専用クライアントライブラリが存在しなかった環境からの利用も可能になりました。
というわけで、今回のブログエントリではこの v4 API を使って Db2 on Cloud のインスタンスにアクセスして SQL を実行し、その実行結果を取得するまでの一連の手順をサンプルアプリケーションとそのコードを参照しつつ紹介します。
【サンプルアプリケーション】
以下で紹介するサンプルアプリケーションの(Node.js 向け)ソースコードはこちらで公開しています:
https://github.com/dotnsf/node-db2
Node.js がインストールされていれば Windows でも Mac でも Linux でも動きます。特にこのアプリケーションは v4 API で作っているので、これまでは(クライアントライブラリが提供されていないため)Db2 にアクセスできなかったラズベリーパイなどの環境からでも利用できる点が特徴になっています。なのでラズパイ環境をお持ちだったらぜひラズパイから利用してみていただきたいです。
サンプルアプリを利用するには、まず IBM Cloud 側の準備が必要です。大まかに以下2段階の準備を行います:
(1)IBM Cloud にログインして Db2 on Cloud サービスインスタンスを作成
(2)作成したインスタンスの接続情報を取得
まず(1)を行います。IBM Cloud に(必要であればアカウントを作成して)ログインし、Db2 サービスインスタンスを作成します:

この際に "Lite" プランを選択しておくとデータ量 200MB 上限や、同時接続数 15 などの制約がありますが、無料で利用することができます:

(1)のインスタンスを作成したら(2)の準備を行います。作成したインスタンスの「サービス資格情報」タブを選択し、「新規資格情報」ボタンで「サービス資格情報」を1つ追加して、その中身を確認します:

以下のような JSON フォーマットの情報を確認することができます:
{
"db": "BLUDB",
"dsn": "DATABASE=BLUDB;HOSTNAME=dashdb-xxx-xxxxx-xxxxxx.services.dal.bluemix.net;PORT=50000;PROTOCOL=TCPIP;UID=username;PWD=password;",
"host": "dashdb-xxx-xxxxx-xxxxxx.services.dal.bluemix.net",
"hostname": "dashdb-xxx-xxxxx-xxxxxx.services.dal.bluemix.net",
"https_url": "https://dashdb-xxx-xxxxx-xxxxxx.services.dal.bluemix.net",
"jdbcurl": "jdbc:db2://dashdb-xxx-xxxxx-xxxxxx.services.dal.bluemix.net:50000/BLUDB",
"parameters": {
"role_crn": "crn:v1:bluemix:public:iam::::serviceRole:Manager"
},
"password": "password",
"port": 50000,
"ssldsn": "DATABASE=BLUDB;HOSTNAME=dashdb-xxx-xxxxx-xxxxxx.services.dal.bluemix.net;PORT=50001;PROTOCOL=TCPIP;UID=username;PWD=password;Security=SSL;",
"ssljdbcurl": "jdbc:db2://dashdb-xxx-xxxxx-xxxxxx.services.dal.bluemix.net:50001/BLUDB:sslConnection=true;",
"uri": "db2://username:password@dashdb-xxx-xxxxx-xxxxxx.services.dal.bluemix.net:50000/BLUDB",
"username": "username"
}ここで必要になるのは以下の3つの値です:
・username
・password
・hostname
加えて deployment id を取得します。この ID はサービス固有の ID で、すべての REST API 実行時に必要な値です。取得方法はサービスを表示しているブラウザ画面の URL を確認します:

おそらくこのようなフォーマットの URL 文字列になっています:
https://cloud.ibm.com/services/dashdb-for-transactions/crn%3Av1%3Abluemix%3Apublic%3Adashdb-for-transactions%3Aus-south%3Aa%2Fxxxxxxxxxxxx%3Axxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx%3A%3A?paneId=manage
この中の "crn" で始まる文字列(? が含まれる場合はその手前まで)を URL デコードした値が deployment id です。URL デコードといってもパターンは2つに決まっていて、"%3A" を ":" に、"%2F" を "/" に変換するだけです。例えば該当の Db2 on Cloud サービスを表示している時の URL 内文字列がこの内容だった場合、
https://cloud.ibm.com/services/dashdb-for-transactions/crn%3Av1%3Abluemix%3Apublic%3Adashdb-for-transactions%3Aus-south%3Aa%2Fxxxxxxxxxxxx%3Axxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx%3A%3A?paneId=manage
deployment id は crn で始まる青字部分を URL デコードした値ということになり、具体的には以下の値となります:
crn:3v1:bluemix:public:dashdb-for-transactions:us-south:a/xxxxxxxxxxxx:xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxx::
以上、ここまでの作業で Db2 on Cloud のサービスインスタンスを作成し、その username, password, hostname, deployment id の4つの情報を取得することができました。この4つの値が取得できれば、実際にサンプルアプリケーションを動かすことができます。
上述のリポジトリ URL から git clone やダウンロード&展開するなどしてソースコード一式を取得します。そして settings.js をテキストエディタで開いて、先程取得した4つの値を入力して保存します:

これでソースコード側に必要な変更も完了です。では実際に Node.js で動かしてみましょう:
$ cd node-db2 $ npm install $ node app
ここまでのコマンドを実行すると、サンプルのウェブアプリケーションは 8080 番ポートで待ち受ける形で起動します。ウェブブラウザ(別 PC からでも可)からサンプルの HTTP リクエストを送信して、Db2 on Cloud で SQL を実行し、その結果を取得します:
http://(上記の $ node app を実行したマシンの IP アドレス):8080/ping
なお、この GET /ping リクエストは Db2 on Cloud インスタンスに対して以下の SQL を実行した結果のシステム情報を取得するように作られたものです:
select TABNAME, TABSCHEMA, OWNER from syscat.tables fetch first 5 rows only;
実際にウェブブラウザでこの URL にアクセスするとこのような結果になります。上述の SQL を実行した結果が JSON で返ってきました。仮にアプリケーションをラズベリーパイ上で動かしていても同様の結果が取得できているはずです。これまでは Db2 のクライアントライブラリが導入できる環境からでないと実行できなかった SQL を、v4 API では(サーバー上のもの以外には)クライアントライブラリを使わない環境でも実行して結果を取得することができる、ということがわかります:

【ソースコード解説】
ではソースコードを見ながら v4 API の解説をします。上述のオペレーションで使っているファイルは変数設定以外は app.js のみなので、全容を確認したい場合はこのファイルを参照ください。
上述で行ったのは1つの SQL を実行して、その結果を取得する、というごく普通のオペレーションですが、v4 API では大きく3つのパートに分かれて処理されています((2)と(3)が別れて処理されている点に注目):
(1)アクセストークン取得
(2)SQL 実行
(3)SQL 結果取得
まず(1)について。これまでの Db2 API では認証時にユーザー名とパスワードがあればログインして SQL を実行することができましたが、v4 API では(今どきらしく)まずアクセストークンを取得して、アクセストークンを付与しながら SQL を実行する必要があります。というわけでアクセストークンの取得手順を紹介します。
具体的には以下のようなコードを実行しているのですが、settings.js に設定した username と password を https://(hostname)/dbapi/v4/auth/tokens に POST しています。またその際の HTTP リクエストヘッダ内で deployment id の値を送付しています(HTTP リクエストヘッダに deployment id を含める、というのは以下すべての REST API で共通です)。成功した場合、返されるオブジェクトの token キーにアクセストークンが付与されて返ってくるので、この値を保存しています(実際のアプリではセッション等に保存しておくべきです):
var access_token = null;
var option = {
url: 'https://' + settings.hostname + '/dbapi/v4/auth/tokens',
json: { userid: settings.username, password: settings.password },
headers: { 'content-type': 'application/json', 'x-deployment-id': settings.deployment_id },
method: 'POST'
};
request( option, async function( err, res0, body ){
if( err ){
console.log( { err } );
}else{
if( body && body.token ){
access_token = body.token;
console.log( { access_token } );
}
}
});
GET /ping にリクエストがあると、このアクセストークンを使って(2)SQL を実行します。app.js では以下のように実行しています:
app.get( '/ping', function( req, res ){
res.contentType( 'application/json; charset=utf-8' );
if( access_token ){
var sql0 = 'select TABNAME, TABSCHEMA, OWNER from syscat.tables fetch first 5 rows only;';
var option0 = {
url: 'https://' + settings.hostname + '/dbapi/v4/sql_jobs',
json: { commands: sql0, limit: 10, separator: ';', stop_on_error: 'no' },
headers: { 'content-type': 'application/json', 'Authorization': 'Bearer ' + access_token, 'x-deployment-id': settings.deployment_id },
method: 'POST'
};
request( option0, async function( err0, res0, body0 ){
if( err0 ){
console.log( { err0 } );
res.status( 400 );
res.write( JSON.stringify( { error: err0 }, null, 2 ) );
res.end();
}else{
if( body0 && body0.id ){
:
:
GET /ping リクエストへのハンドラとして、まず "select TABNAME, TABSCHEMA, OWNER from syscat.tables fetch first 5 rows only;" という SQL を https://(hostname)/dbapi/v4/sql_jobs に POST して実行しています。この処理が成功すると、返されるオブジェクトに id というキー値が含まれています。
そして(3)では、実行した SQL の結果を取得します。その際には(2)で取得した id キー値を指定して GET https://(hostname)/dbapi/v4/sql_jobs/(id) を実行して、その結果が先程のブラウザ画面のようなフォーマットで取得されていたのでした:
:
:
if( body0 && body0.id ){
console.log( { body0 } );
var option1 = {
url: 'https://' + settings.hostname + '/dbapi/v4/sql_jobs/' + body0.id,
headers: { 'content-type': 'application/json', 'Authorization': 'Bearer ' + access_token, 'x-deployment-id': settings.deployment_id },
method: 'GET'
};
request( option1, async function( err1, res1, body1 ){
if( err1 ){
console.log( { err1 } );
res.status( 400 );
res.write( JSON.stringify( { error: err1 }, null, 2 ) );
res.end();
}else{
//. body1 は string
body1 = JSON.parse( body1 );
console.log( { body1 } );
res.write( JSON.stringify( body1, null, 2 ) );
res.end();
}
});
}else{
res.status( 400 );
res.write( JSON.stringify( { error: body0 }, null, 2 ) );
res.end();
}
}
});
}else{
res.status( 400 );
res.write( JSON.stringify( { error: 'no access_token' }, null, 2 ) );
res.end();
}
});
NoSQL とは違って、トランザクションを含む(時間のかかる)処理を実行する可能性もあるため、その間で処理をブロックしないようにこのような仕様で API が用意されているのだと思います。上の例では SQL の実行と結果の取得を続けて行って実行結果を返していますが、(途中に取得できる id をいったんクライアントに返すことで)これら2つの処理を別の REST API で分けて実行させることも可能になります。シングルスレッドの Node.js での実装を考慮すると、こちらのほうがより正しいといえるかもしれません。
【良い点・悪い点】
なんといっても「ラズベリーパイなどの、Db2 クライアントライブラリが提供されていないシステムから Db2 サーバーに接続してクエリーを実行できる」ようになったことが大きな改善点であると感じました。また時間のかかる処理を実行する際にも、まとめて実行して、その間の他のリクエストをブロックすることなく、後から結果を確認できるようになっている点もクラウド時代らしいといえます。
唯一残念な点は「プレースホルダー型の SQL に未対応」な点です。SQL を比較的安全に実行する上でよく使われるプレースホルダー型の SQL("SELECT * from xxxxx where id = ?" で、パラメーターの id を分けて送って実行する SQL)には現時点ではこの REST API では未対応のようで、現時点では開発者が気をつけて実装するか、(クライアントライブラリが提供されているシステムから)従来の専用ライブラリを使って実行する必要がありそうでした。
【参考】
IBM Db2 on Cloud REST API


コメント