IBM Bluemix から提供されているコグニティブエンジン Watson Visual Recognition サービスは画像をインプットとして与えると、その画像が何の画像なのか?をその確実度合いと併せてアウトプットしてくれる、という画像認識 API です(このページからサンプルデモアプリを動かして確認することができます):

この API はあらかじめ学習済みのモデルを素に、確率の高そうな認識結果を返してくれる、という API ですが、この仕様の裏を返すと、既に学習済みの一般的な判断結果しか返してくれない、ということになります。「この画像、本当は○○という結果を返してほしいんだよなあ」と思っても、その○○を学習していない状態では(ワトソンからすればそもそも知らない選択肢ということになるので)そのような判断をすることもできないのでした。
しかし、12月に Visual Recognition API が V2 にバージョンアップし、これまでの V1 API には存在しなかった学習 API も使えるようになりました。この API で自分に都合よい画像サンプルとその分類結果を学習させておけば、自分の望む識別結果を返してくれるようになる、、、かもしれません。
なお、Visual Recognition V2 の詳しい API の仕様については以下のリファレンスページを参照してください:
https://watson-api-explorer.mybluemix.net/apis/visual-recognition-v2-beta
改めて、ではその新機能である学習 API の使い方と、学習させた結果の認識がどのように変わるのか、を調べた様子を紹介します。
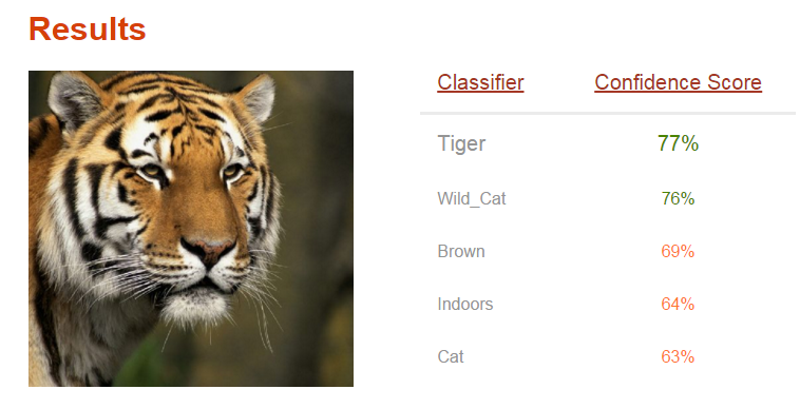
まず「画像を学習させる」とはどのようなことなのかを理解する必要があります。例えば上記デモ結果画像のトラの画像を認識させた結果を見ると、以下のようになっています:
この認識結果として表示されている候補のテキスト("Tiger" や "Wild_Cat")それぞれのことを classifier(分類カテゴリ)と呼びます。Visual Recognition API にはあらかじめ複数の classifiers が学習済みで用意されており、カスタマイズする前であれば、あらかじめ学習済みの内容だけを対象に認識・識別を行います。
Visual Recognition API V2 で新たに追加された機能とは、この classifier を独自に追加できるようになる、というものです。追加の際には以下の3つの情報が必要となります:
(1) 追加する classifier の名前(上記の "Tiger" や "Wild_Cat" に相当する部分)
(2) 追加する classifier に分類される画像例
(3) classifier に分類されない画像例
(1) は認識結果としてどのように表示してほしいか、という名称なので、これは任意のテキストを指定できます。では例えばここでは "Manhole"(マンホール)というカテゴリを認識できるようにしたいとしましょう。
そして (2) はその目的の名称として認識される画像のサンプルです。画像サンプルは 200x200 以上の解像度を持ったイメージで、学習には 50 枚以上が必要となります(枚数が多いほど精度が高くなります)。つまりこの場合であれば 200x200 以上の解像度を持った典型的なマンホールの画像を 50 枚以上用意する必要がある、ということになります。
その画像をどうやって集めるか、が問題になりますが、ここではマンホールマップの人気画像 100 個を集めてきました。「人気がある」=「典型的」かどうかは何とも言えませんが、マンホールとして分類してほしい画像のサンプルになりえる画像集、です:
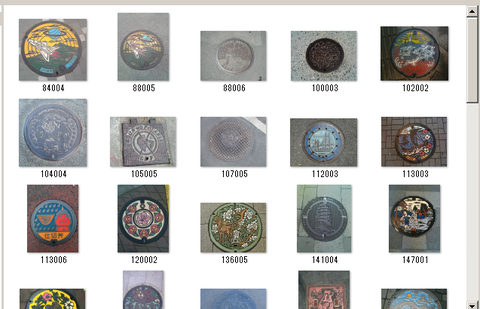
↑マンホール画像100枚
今回は 100 枚の画像を集めました。API として学習させる際には zip ファイルとしてまとめて転送することになるので、これら 100 枚の画像を posi.zip というファイルにまとめておきました。
次に (3) の「マンホールではない画像のサンプル」を用意します。これは正確には「マンホールに見間違えるかもしれないけど、マンホールではない画像のサンプル」です。「マンホールに間違えるかもしれない」という部分をどう考えたらよいのかよくわかりませんが、とりあえず「丸い画像」を 100 枚集めてみました:

↑丸いけどマンホールではない画像100枚
これらのファイルも API 利用時には zip ファイルとして指定する必要があるため、nega.zip という zip ファイルにまとめました。
実際にはこの「サンプル画像を用意する」のがかなり大変な作業だと思います。認識して欲しい画像のサンプルは比較的容易に集められるかもしれませんが、「似てるけど認識して欲しくない画像」とはそもそも何を探せばよいのかも難しいのです。しかも 200x200 以上の画像で、50 枚以上用意する必要があります。現実にはこの部分の作業には手間もかかるだろうし、かなり大変だと思っています。
(1), (2), (3) 全て用意できたら、実際に学習させてみましょう。IBM Bluemix に Watson Visual Recognition サービスを追加し、その資格情報から username と password を確認しておきます(username と password が、それぞれ (username) と (password) であると仮定して以下を説明します):

まずは学習前の classifiers 一覧を確認してみましょう。curl を使って以下のコマンドを実行します(青字が実行結果です)。なお指定するエンドポイント URL に必ず version パラメータを付与する(値は 2015-12-02 を指定する)ことに注意してください:
実行結果には classifiers という名前の配列が含まれており、その中が現時点での classifiers 一覧になっています。要するに何も学習させていないこの段階で Visual Recognition API V2 で画像を認識させると、この一覧の中のどの属性に近い画像であったのかを調べて、その結果が出力される、ということです。この一覧の中には "name" 値が "Manhole" という classifier はありません。つまり少なくとも "Manhole" という結果が返されることはないわけです。
いったん、この(学習前の)状態でマンホールの画像をポストしてどのように認識されるかを確認してみましょう。題材に使うのはこの画像とします(先程の posi.zip には含まれていない画像です):

この画像を file.png という名前で保存した上で、以下のコマンドを実行して画像認識を実行してみます:
学習前のデフォルト状態では "Fashion_Accessory" や "Meter" の可能性が高い、という認識結果になりました。まだ "Manhole" を学習してない状態ではこのような結果になりましたが、ではこれを "Manhole" と認識してもらえるように先程用意したポジティブ&ネガティブ画像を使って学習させることにします。
(2) で用意した posi.zip と、(3) で用意した nega.zip を同じディレクトリに用意したら、実際に API を実行して学習させてみます。2つの zip ファイルをカレントディレクトリに用意した状態で以下のコマンドを実行します:
↑コマンド実行後、しばらく学習が続きますが、その間はプロンプトが戻ってきません(ハングったように見えます)。しばらく待った後に上記の青字部分が実行結果として返ってきます。上記のように classifier_id と name が含まれる結果が返っていれば学習が完了したことを示しています。
"Manhole" を覚えたはずなので、この状態で再度 classifiers 一覧を取得してみましょう:
先程の実行結果に含まれていなかった "Manhole" の classifier が含まれています。つまりこの段階で画像認識 API を使うと、"Manhole" という結果が帰ってくる可能性がある状態にできました。
では改めてこの状態で先程試した画像を使って画像認識を実行してみます:
一応、最も確率の高い結果として "Manhole" を得ることができました。2位に先程まで1位だった "Fasshon_Accessory" が入っていて、学習に使った 100 枚のマンホールが有効に働いて今回のこの結果が得られているようです。
ではもう一つ。これも先程の学習に使わなかった(nega.zip に含まれていない)この画像を問い合わせて見ることにします:

デザイン的にはちょっとマンホールっぽく見えないこともないこの画像を Visual Recognition に問い合わせるとどういう結果になるのでしょうか?やはり file.png という名前で保存して実行してみました。実際の結果がこちらです:
"White" や "Snow_Sport", "Winter_Scene" といった辺りの分類が高い可能性として挙げられています。画像全体が白いとそういう結果になるんですかね。 そして "Manhole" はリストの最後に出てきてはいますが、あまり確率が高いとはいえないことがわかります。これもある意味で正しく Negative の学習ができていると判断できるかもしれません。
以上のように、新しくなった Watson Visual Recognition API ではサンプル画像を用意して新しい認識結果の学習が出来ることがわかりました。その結果も少なくともとんちんかんなものではなさそうな印象です。 画像のパターン認識について意識することなく学習させることができる、というのは便利に使えそうです。
ともあれ、それなりに正しく動きそうなマンホール画像学習ができました。これは近日中にマンホールマップに実装予定です。
(参考)
http://qiita.com/mfujita/items/a6bfcffae8097807f6a0
この API はあらかじめ学習済みのモデルを素に、確率の高そうな認識結果を返してくれる、という API ですが、この仕様の裏を返すと、既に学習済みの一般的な判断結果しか返してくれない、ということになります。「この画像、本当は○○という結果を返してほしいんだよなあ」と思っても、その○○を学習していない状態では(ワトソンからすればそもそも知らない選択肢ということになるので)そのような判断をすることもできないのでした。
しかし、12月に Visual Recognition API が V2 にバージョンアップし、これまでの V1 API には存在しなかった学習 API も使えるようになりました。この API で自分に都合よい画像サンプルとその分類結果を学習させておけば、自分の望む識別結果を返してくれるようになる、、、かもしれません。
なお、Visual Recognition V2 の詳しい API の仕様については以下のリファレンスページを参照してください:
https://watson-api-explorer.mybluemix.net/apis/visual-recognition-v2-beta
改めて、ではその新機能である学習 API の使い方と、学習させた結果の認識がどのように変わるのか、を調べた様子を紹介します。
まず「画像を学習させる」とはどのようなことなのかを理解する必要があります。例えば上記デモ結果画像のトラの画像を認識させた結果を見ると、以下のようになっています:
| 認識結果 | その確実度 |
|---|---|
| Tiger | 77% |
| Wild_Cat | 76% |
| Brown | 69% |
| Indoors | 64% |
| Cat | 63% |
この認識結果として表示されている候補のテキスト("Tiger" や "Wild_Cat")それぞれのことを classifier(分類カテゴリ)と呼びます。Visual Recognition API にはあらかじめ複数の classifiers が学習済みで用意されており、カスタマイズする前であれば、あらかじめ学習済みの内容だけを対象に認識・識別を行います。
Visual Recognition API V2 で新たに追加された機能とは、この classifier を独自に追加できるようになる、というものです。追加の際には以下の3つの情報が必要となります:
(1) 追加する classifier の名前(上記の "Tiger" や "Wild_Cat" に相当する部分)
(2) 追加する classifier に分類される画像例
(3) classifier に分類されない画像例
(1) は認識結果としてどのように表示してほしいか、という名称なので、これは任意のテキストを指定できます。では例えばここでは "Manhole"(マンホール)というカテゴリを認識できるようにしたいとしましょう。
そして (2) はその目的の名称として認識される画像のサンプルです。画像サンプルは 200x200 以上の解像度を持ったイメージで、学習には 50 枚以上が必要となります(枚数が多いほど精度が高くなります)。つまりこの場合であれば 200x200 以上の解像度を持った典型的なマンホールの画像を 50 枚以上用意する必要がある、ということになります。
その画像をどうやって集めるか、が問題になりますが、ここではマンホールマップの人気画像 100 個を集めてきました。「人気がある」=「典型的」かどうかは何とも言えませんが、マンホールとして分類してほしい画像のサンプルになりえる画像集、です:
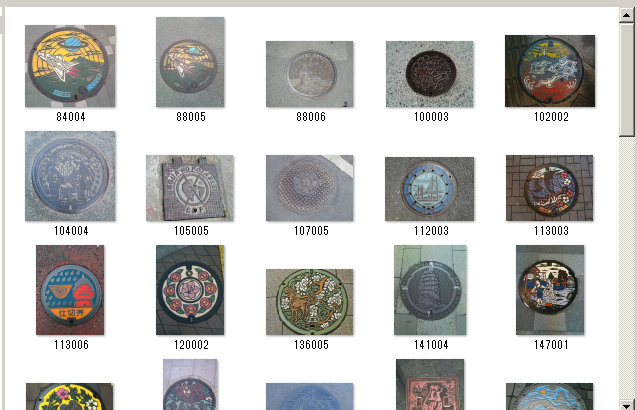
↑マンホール画像100枚
今回は 100 枚の画像を集めました。API として学習させる際には zip ファイルとしてまとめて転送することになるので、これら 100 枚の画像を posi.zip というファイルにまとめておきました。
次に (3) の「マンホールではない画像のサンプル」を用意します。これは正確には「マンホールに見間違えるかもしれないけど、マンホールではない画像のサンプル」です。「マンホールに間違えるかもしれない」という部分をどう考えたらよいのかよくわかりませんが、とりあえず「丸い画像」を 100 枚集めてみました:

↑丸いけどマンホールではない画像100枚
これらのファイルも API 利用時には zip ファイルとして指定する必要があるため、nega.zip という zip ファイルにまとめました。
実際にはこの「サンプル画像を用意する」のがかなり大変な作業だと思います。認識して欲しい画像のサンプルは比較的容易に集められるかもしれませんが、「似てるけど認識して欲しくない画像」とはそもそも何を探せばよいのかも難しいのです。しかも 200x200 以上の画像で、50 枚以上用意する必要があります。現実にはこの部分の作業には手間もかかるだろうし、かなり大変だと思っています。
(1), (2), (3) 全て用意できたら、実際に学習させてみましょう。IBM Bluemix に Watson Visual Recognition サービスを追加し、その資格情報から username と password を確認しておきます(username と password が、それぞれ (username) と (password) であると仮定して以下を説明します):
まずは学習前の classifiers 一覧を確認してみましょう。curl を使って以下のコマンドを実行します(青字が実行結果です)。なお指定するエンドポイント URL に必ず version パラメータを付与する(値は 2015-12-02 を指定する)ことに注意してください:
# curl -u "(username)":"(password)" https://gateway.watsonplatform.net/visual-recognition-beta/api/v2/classifiers?version=2015-12-02
{ "classifiers":[
{"classifier_id":"Black","name":"Black"},
{"classifier_id":"Blue","name":"Blue"},
{"classifier_id":"Brown","name":"Brown"},
{"classifier_id":"Cyan","name":"Cyan"},
{"classifier_id":"Green","name":"Green"},
{"classifier_id":"Magenta","name":"Magenta"},
{"classifier_id":"Mixed_Color","name":"Mixed_Color"},
{"classifier_id":"Orange","name":"Orange"},
:
:
{"classifier_id":"Sunset","name":"Sunset"}]
}
実行結果には classifiers という名前の配列が含まれており、その中が現時点での classifiers 一覧になっています。要するに何も学習させていないこの段階で Visual Recognition API V2 で画像を認識させると、この一覧の中のどの属性に近い画像であったのかを調べて、その結果が出力される、ということです。この一覧の中には "name" 値が "Manhole" という classifier はありません。つまり少なくとも "Manhole" という結果が返されることはないわけです。
いったん、この(学習前の)状態でマンホールの画像をポストしてどのように認識されるかを確認してみましょう。題材に使うのはこの画像とします(先程の posi.zip には含まれていない画像です):
この画像を file.png という名前で保存した上で、以下のコマンドを実行して画像認識を実行してみます:
# curl -u "(username)":"(password)" -X POST -F "images_file=@file.png" https://gateway.watsonplatform.net/visual-recognition-beta/api/v2/classify?version=2015-12-02
{"images":[
{"image":file.png",
"scores":[
{"classifier_id":"Fashion_Accessory","name":"Fashion_Accessory","score":0.645613},
{"classifier_id":"Meter","name":"Meter","score":0.618349},
{"classifier_id":"Mixed_Color","name":"Mixed_Color","score":0.608368},
{"classifier_id":"Chocolate_Mousse","name":"Chocolate_Mousse","score":0.595259},
{"classifier_id":"Chocolate_Mousse","name":"Chocolate_Mousse","score":0.595259},
{"classifier_id":"Disturbance","name":"Disturbance","score":0.58813},
{"classifier_id":"Subway_Platform","name":"Subway_Platform","score":0.572388},
{"classifier_id":"Skibob","name":"Skibob","score":0.556545},
{"classifier_id":"Road_Traffic_Scene","name":"Road_Traffic_Scene","score":0.549438},
{"classifier_id":"Auto_Factory","name":"Auto_Factory","score":0.53405},
{"classifier_id":"Kayaking","name":"Kayaking","score":0.529446},
{"classifier_id":"Gym","name":"Gym","score":0.512764}]}]
}
学習前のデフォルト状態では "Fashion_Accessory" や "Meter" の可能性が高い、という認識結果になりました。まだ "Manhole" を学習してない状態ではこのような結果になりましたが、ではこれを "Manhole" と認識してもらえるように先程用意したポジティブ&ネガティブ画像を使って学習させることにします。
(2) で用意した posi.zip と、(3) で用意した nega.zip を同じディレクトリに用意したら、実際に API を実行して学習させてみます。2つの zip ファイルをカレントディレクトリに用意した状態で以下のコマンドを実行します:
# curl -X POST -u "(username)":"(password)" -F "positive_examples=@posi.zip" -F "negative_examples=@nega.zip" -F "name=Manhole" https://gateway.watsonplatform.net/visual-recognition-beta/api/v2/classifiers?version=2015-12-02
{
"name" : "Manhole",
"classifier_id" : "Manhole_1277505833",
"created" : "2015-12-21T05:59:30.000Z",
"owner" : "de3f195e-890a-4e87-834f-9d728abd863c-us-south"
}
↑コマンド実行後、しばらく学習が続きますが、その間はプロンプトが戻ってきません(ハングったように見えます)。しばらく待った後に上記の青字部分が実行結果として返ってきます。上記のように classifier_id と name が含まれる結果が返っていれば学習が完了したことを示しています。
"Manhole" を覚えたはずなので、この状態で再度 classifiers 一覧を取得してみましょう:
# curl -u "(username)":"(password)" https://gateway.watsonplatform.net/visual-recognition-beta/api/v2/classifiers?version=2015-12-02
{ "classifiers":[
{"classifier_id":"Manhole_1277505833","name":"Manhole"},
{"classifier_id":"Black","name":"Black"},
{"classifier_id":"Blue","name":"Blue"},
{"classifier_id":"Brown","name":"Brown"},
{"classifier_id":"Cyan","name":"Cyan"},
{"classifier_id":"Green","name":"Green"},
{"classifier_id":"Magenta","name":"Magenta"},
{"classifier_id":"Mixed_Color","name":"Mixed_Color"},
{"classifier_id":"Orange","name":"Orange"},
:
:
{"classifier_id":"Sunset","name":"Sunset"}]
}
先程の実行結果に含まれていなかった "Manhole" の classifier が含まれています。つまりこの段階で画像認識 API を使うと、"Manhole" という結果が帰ってくる可能性がある状態にできました。
では改めてこの状態で先程試した画像を使って画像認識を実行してみます:
# curl -u "(username)":"(password)" -X POST -F "images_file=@file.png" https://gateway.watsonplatform.net/visual-recognition-beta/api/v2/classify?version=2015-12-02 {"images":[ {"image":file.png", "scores":[ {"classifier_id":"Manhole_1277505833","name":"Manhole","score":0.776738}, {"classifier_id":"Fashion_Accessory","name":"Fashion_Accessory","score":0.645613}, {"classifier_id":"Meter","name":"Meter","score":0.618349}, {"classifier_id":"Mixed_Color","name":"Mixed_Color","score":0.608368}, {"classifier_id":"Chocolate_Mousse","name":"Chocolate_Mousse","score":0.595259}, {"classifier_id":"Chocolate_Mousse","name":"Chocolate_Mousse","score":0.595259}, {"classifier_id":"Disturbance","name":"Disturbance","score":0.58813}, {"classifier_id":"Subway_Platform","name":"Subway_Platform","score":0.572388}, {"classifier_id":"Skibob","name":"Skibob","score":0.556545}, {"classifier_id":"Road_Traffic_Scene","name":"Road_Traffic_Scene","score":0.549438}, {"classifier_id":"Auto_Factory","name":"Auto_Factory","score":0.53405}, {"classifier_id":"Kayaking","name":"Kayaking","score":0.529446}, {"classifier_id":"Gym","name":"Gym","score":0.512764}]}] }
一応、最も確率の高い結果として "Manhole" を得ることができました。2位に先程まで1位だった "Fasshon_Accessory" が入っていて、学習に使った 100 枚のマンホールが有効に働いて今回のこの結果が得られているようです。
ではもう一つ。これも先程の学習に使わなかった(nega.zip に含まれていない)この画像を問い合わせて見ることにします:
デザイン的にはちょっとマンホールっぽく見えないこともないこの画像を Visual Recognition に問い合わせるとどういう結果になるのでしょうか?やはり file.png という名前で保存して実行してみました。実際の結果がこちらです:
# curl -u "(username)":"(password)" -X POST -F "images_file=@file.png" https://gateway.watsonplatform.net/visual-recognition-beta/api/v2/classify?version=2015-12-02 {"images":[ {"image":file.png", "scores":[ {"classifier_id":"White","name":"White","score":0.707564}, {"classifier_id":"Snow_Sport","name":"Snow_Sport","score":0.687052}, {"classifier_id":"Winter_Scene","name":"Winter_Scene","score":0.648243}, {"classifier_id":"Skiing","name":"Skiing","score":0.648041}, {"classifier_id":"Outdoors","name":"Outdoors","score":0.64775}, {"classifier_id":"Winter_Sport","name":"Winter_Sport","score":0.636656}, {"classifier_id":"Blow_Dryer","name":"Blow_Dryer","score":0.636557}, {"classifier_id":"Sky_Scene","name":"Sky_Scene","score":0.616727}, {"classifier_id":"Appliance","name":"Appliance","score":0.615328}, {"classifier_id":"Ski_Jumping","name":"Ski_Jumping","score":0.587443}, {"classifier_id":"Gray_Sky","name":"Gray_Sky","score":0.582471}, {"classifier_id":"Tool","name":"Tool","score":0.580808}, {"classifier_id":"Nature_Scene","name":"Nature_Scene","score":0.573698}, {"classifier_id":"Belt","name":"Belt","score":0.572148}, {"classifier_id":"Snow_Scene","name":"Snow_Scene","score":0.563831}, {"classifier_id":"Statue_of_Liberty","name":"Statue_of_Liberty","score":0.514912}, {"classifier_id":"Black_and_white","name":"Black_and_white","score":0.505201}, {"classifier_id":"Manhole_1277505833","name":"Manhole","score":0.5009}]}] }
"White" や "Snow_Sport", "Winter_Scene" といった辺りの分類が高い可能性として挙げられています。画像全体が白いとそういう結果になるんですかね。 そして "Manhole" はリストの最後に出てきてはいますが、あまり確率が高いとはいえないことがわかります。これもある意味で正しく Negative の学習ができていると判断できるかもしれません。
以上のように、新しくなった Watson Visual Recognition API ではサンプル画像を用意して新しい認識結果の学習が出来ることがわかりました。その結果も少なくともとんちんかんなものではなさそうな印象です。 画像のパターン認識について意識することなく学習させることができる、というのは便利に使えそうです。
ともあれ、それなりに正しく動きそうなマンホール画像学習ができました。これは近日中にマンホールマップに実装予定です。
(参考)
http://qiita.com/mfujita/items/a6bfcffae8097807f6a0


コメント