IBM Cloud から提供されている 30 日間無料 Kubernetes サービス(IBM Kubernetes Service 、以下 "IKS")環境を使って利用することのできるコンテナイメージを1日に1個ずつ 30 日間連続で紹介していきます。
環境のセットアップや制約事項については Day0 のこちらの記事を参照してください。
Day 25 からはアプリケーション系コンテナとその GUI ツールを中心に紹介してます。最終日である Day 30 は集大成として世の中の大半のウェブコンテンツを管理していると思われる WordPress イメージをデプロイする例を紹介します。

【イメージの概要】
ブログなどのウェブコンテンツを管理・編集・公開するシステムです。
個人的にも WordPress には思い入れがあります。業務とは関係のないところで WordPress を知って、勉強して、そこから自分のキャリアが変わるきっかけにもなりました。今の自分が今の立場でいるのは WordPress との関わりがあったからだと思っています。そんな背景もあって 30 日間連続ブログの最終日に紹介するコンテンツとさせていただきました。
WordPress の動作時にはデータベースが必要なのですが、今回は MySQL を使う方法を紹介します。MySQL 単体のデプロイについては Day 6 でも紹介しているので、必要に応じて参照してください。
【イメージのデプロイ】
まずはこれら2つのファイルを自分の PC にダウンロードしてください:
https://raw.githubusercontent.com/dotnsf/yamls_for_iks/main/mysql.yaml
https://raw.githubusercontent.com/dotnsf/yamls_for_iks/main/wordpress.yaml
前者が MySQL 用、後者が WordPress 用のデプロイファイルです(両方使います)。
前者の MySQL 用デプロイファイルは Day 6 で行ったものと同様の編集が必要です。mysql.yaml ファイルをテキストエディタで開いて、 "MYSQL_" で始まる4箇所の env.name の value 値を変更してください。それぞれの具体的な意味は以下の通りです(初期値として指定されている値のまま動かすことも可能ですが、安全のためなるべく変更してください):
・MYSQL_ROOT_PASSWORD : 管理者パスワード(初期値 P@ssw0rd)
・MYSQL_DATABASE : デプロイと同時に作成するデータベースの名前(初期値 mydb)
・MYSQL_USER : デプロイと同時に作成するデータベースを利用するユーザー名(初期値 user1)
・MYSQL_PASSWORD : デプロイと同時に作成するデータベースを利用するパスワード(初期値 password1)
また後者の WordPress 用デプロイファイルには4箇所の変種が必要です。wordpress.yaml ファイルをテキストエディタで開いて、 "WORDPRESS_" で始まる4箇所の env.name の value 値を変更してください。それぞれの具体的な意味は以下の通りです。特に WORDPRESS_DB_HOST の値は後述する IP アドレスと上述の MySQL に設定した値を両方参照して入力する必要がある点に注意ください:
・WORDPRESS_DB_HOST : MySQL のホスト名とポート番号(初期値 xxx.xxx.xxx.xxx:30306)
・WORDPRESS_DB_USER : MySQL に接続するユーザー名(初期値 user1)
・WORDPRESS_DB_PASSWORD : MySQL に接続するパスワード(初期値 password1)
・WORDPRESS_DB_NAME : MySQL の DB 名(初期値 mydb)
ではこのダウンロード&編集した2つの yaml ファイルを指定してデプロイします。以下のコマンドを実行する前に Day 0 の内容を参照して ibmcloud CLI ツールで IBM Cloud にログインし、クラスタに接続するまでを済ませておいてください。
そして以下のコマンドを実行します:
以下のコマンドで MySQL 関連の Deployment, Service, Pod, Replicaset が1つずつ生成されたことと、サービスが 30306 番ポートで公開されていること、そして WordPress 関連も同様に Deployment, Service, Pod, Replicaset が1つずつ生成され、サービスが 30080 番ポートで公開されていることを確認します:
この後に実際にサービスを利用するため、以下のコマンドでワーカーノードのパブリック IP アドレスを確認します(以下の例であれば 161.51.204.190):
つまりこの時点で(上述の結果であれば)アプリケーションは http://169.51.204.190:30080/ で稼働している、ということになります。ウェブブラウザを使って、アプリケーションの URL(上述の方法で確認した URL)にアクセスしてみます:
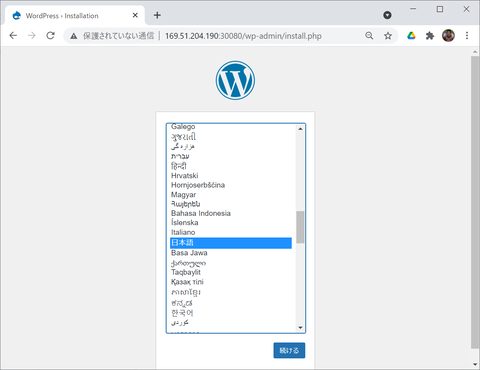
WordPress をインストールしたことがある人にはお馴染みの初期セットアップ画面が表示されます。とりあえず無事に IKS 内で WordPress が稼働できているようです。
Drupal の時とは異なり、データベース接続情報などはデプロイ時に既に指定しているので、サイトの情報を入力するだけで使えるようになります:
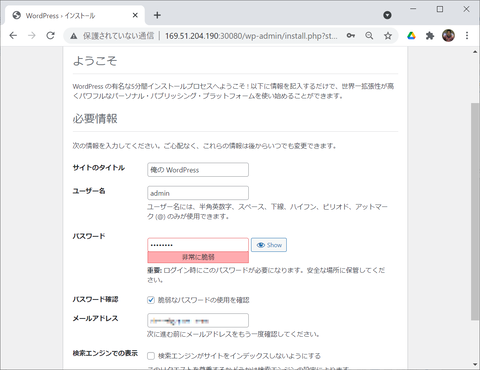
セットアップが無事に成功しました。あとはセットアップ時に指定したユーザー&パスワードでログインすれば管理画面にアクセスできるようになります:
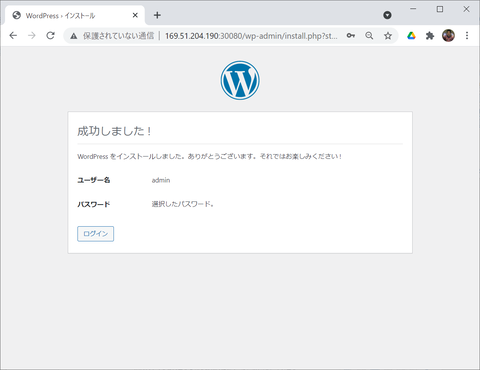
WordPress のコンテンツ管理画面にアクセスできました。IKS 内で WordPress を起動できました:
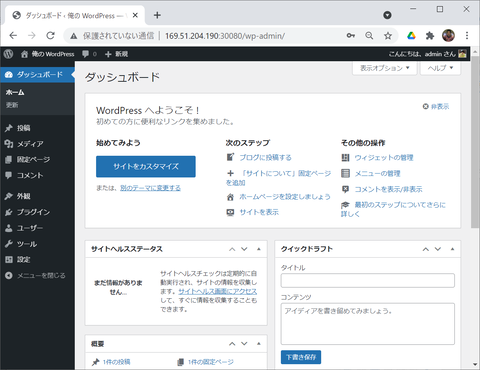
Drupal の時と同様ですが、コンテンツフォルダを共有していないので、インスタンス数を2以上に増やして使うことはできませんが、とりあえず WordPress が動く環境を作ることができました。
【YAML ファイルの解説】
WordPress の YAML ファイルはこちらを使っています(MySQL の YAML ファイルについては Day 6 参照):
Deployment 1つと、Service 1つ、環境変数の指定も不要で本シリーズで紹介する 30 個の中でも指折りにシンプルな YAML ファイルです。一応解説を加えておきます。アプリケーションそのものは 80 番ポートで動作するように作られているため、NodePort 30080 番を指定して、外部からは 30080 番ポートでアクセスできるようにしています(NodePort として指定可能な番号の範囲は 30000 ~ 32767 です、指定しない場合は空いている番号がランダムに割り振られます)。また ReplicaSet は1つだけで作りました。
デプロイしたコンテナイメージを削除する場合はデプロイ時に使った YAML ファイルを再度使って、以下のコマンドを実行します。不要であれば削除しておきましょう:
【紹介したイメージ】
https://hub.docker.com/_/wordpress
【紹介記録】
ついに 30 日間 30 イメージ紹介を達成しました!
環境のセットアップや制約事項については Day0 のこちらの記事を参照してください。
Day 25 からはアプリケーション系コンテナとその GUI ツールを中心に紹介してます。最終日である Day 30 は集大成として世の中の大半のウェブコンテンツを管理していると思われる WordPress イメージをデプロイする例を紹介します。

【イメージの概要】
ブログなどのウェブコンテンツを管理・編集・公開するシステムです。
個人的にも WordPress には思い入れがあります。業務とは関係のないところで WordPress を知って、勉強して、そこから自分のキャリアが変わるきっかけにもなりました。今の自分が今の立場でいるのは WordPress との関わりがあったからだと思っています。そんな背景もあって 30 日間連続ブログの最終日に紹介するコンテンツとさせていただきました。
WordPress の動作時にはデータベースが必要なのですが、今回は MySQL を使う方法を紹介します。MySQL 単体のデプロイについては Day 6 でも紹介しているので、必要に応じて参照してください。
【イメージのデプロイ】
まずはこれら2つのファイルを自分の PC にダウンロードしてください:
https://raw.githubusercontent.com/dotnsf/yamls_for_iks/main/mysql.yaml
https://raw.githubusercontent.com/dotnsf/yamls_for_iks/main/wordpress.yaml
前者が MySQL 用、後者が WordPress 用のデプロイファイルです(両方使います)。
前者の MySQL 用デプロイファイルは Day 6 で行ったものと同様の編集が必要です。mysql.yaml ファイルをテキストエディタで開いて、 "MYSQL_" で始まる4箇所の env.name の value 値を変更してください。それぞれの具体的な意味は以下の通りです(初期値として指定されている値のまま動かすことも可能ですが、安全のためなるべく変更してください):
・MYSQL_ROOT_PASSWORD : 管理者パスワード(初期値 P@ssw0rd)
・MYSQL_DATABASE : デプロイと同時に作成するデータベースの名前(初期値 mydb)
・MYSQL_USER : デプロイと同時に作成するデータベースを利用するユーザー名(初期値 user1)
・MYSQL_PASSWORD : デプロイと同時に作成するデータベースを利用するパスワード(初期値 password1)
また後者の WordPress 用デプロイファイルには4箇所の変種が必要です。wordpress.yaml ファイルをテキストエディタで開いて、 "WORDPRESS_" で始まる4箇所の env.name の value 値を変更してください。それぞれの具体的な意味は以下の通りです。特に WORDPRESS_DB_HOST の値は後述する IP アドレスと上述の MySQL に設定した値を両方参照して入力する必要がある点に注意ください:
・WORDPRESS_DB_HOST : MySQL のホスト名とポート番号(初期値 xxx.xxx.xxx.xxx:30306)
・WORDPRESS_DB_USER : MySQL に接続するユーザー名(初期値 user1)
・WORDPRESS_DB_PASSWORD : MySQL に接続するパスワード(初期値 password1)
・WORDPRESS_DB_NAME : MySQL の DB 名(初期値 mydb)
ではこのダウンロード&編集した2つの yaml ファイルを指定してデプロイします。以下のコマンドを実行する前に Day 0 の内容を参照して ibmcloud CLI ツールで IBM Cloud にログインし、クラスタに接続するまでを済ませておいてください。
そして以下のコマンドを実行します:
$ kubectl apply -f mysql.yaml
$ kubectl apply -f wordpress.yaml
以下のコマンドで MySQL 関連の Deployment, Service, Pod, Replicaset が1つずつ生成されたことと、サービスが 30306 番ポートで公開されていること、そして WordPress 関連も同様に Deployment, Service, Pod, Replicaset が1つずつ生成され、サービスが 30080 番ポートで公開されていることを確認します:
$ kubectl get all NAME READY STATUS RESTARTS AGE pod/mysql-5bd77967b-z9lcl 1/1 Running 0 104s pod/wordpress-67848cd6b-296kh 1/1 Running 0 62s NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE service/kubernetes ClusterIP 172.21.0.1 <none> 443/TCP 27d service/mysqlserver NodePort 172.21.89.71 <none> 3306:30306/TCP 105s service/wordpress NodePort 172.21.140.192 <none> 80:30080/TCP 63s NAME READY UP-TO-DATE AVAILABLE AGE deployment.apps/mysql 1/1 1 1 106s deployment.apps/wordpress 1/1 1 1 64s NAME DESIRED CURRENT READY AGE replicaset.apps/mysql-5bd77967b 1 1 1 106s replicaset.apps/wordpress-67848cd6b 1 1 1 64s
この後に実際にサービスを利用するため、以下のコマンドでワーカーノードのパブリック IP アドレスを確認します(以下の例であれば 161.51.204.190):
$ ibmcloud ks worker ls --cluster=mycluster-free
OK
ID パブリック IP プライベート IP フレーバー 状態 状況 ゾーン バージョン
kube-c3biujbf074rs3rl76t0-myclusterfr-default-000000df 169.51.204.190 10.144.185.144 free normal Ready mil01 1.20.7_1543*
つまりこの時点で(上述の結果であれば)アプリケーションは http://169.51.204.190:30080/ で稼働している、ということになります。ウェブブラウザを使って、アプリケーションの URL(上述の方法で確認した URL)にアクセスしてみます:

WordPress をインストールしたことがある人にはお馴染みの初期セットアップ画面が表示されます。とりあえず無事に IKS 内で WordPress が稼働できているようです。
Drupal の時とは異なり、データベース接続情報などはデプロイ時に既に指定しているので、サイトの情報を入力するだけで使えるようになります:

セットアップが無事に成功しました。あとはセットアップ時に指定したユーザー&パスワードでログインすれば管理画面にアクセスできるようになります:

WordPress のコンテンツ管理画面にアクセスできました。IKS 内で WordPress を起動できました:

Drupal の時と同様ですが、コンテンツフォルダを共有していないので、インスタンス数を2以上に増やして使うことはできませんが、とりあえず WordPress が動く環境を作ることができました。
【YAML ファイルの解説】
WordPress の YAML ファイルはこちらを使っています(MySQL の YAML ファイルについては Day 6 参照):
apiVersion: v1
kind: Service
metadata:
name: wordpress
spec:
selector:
app: wordpress
ports:
- port: 80
protocol: TCP
targetPort: 80
nodePort: 30080
type: NodePort
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: wordpress
spec:
replicas: 1
selector:
matchLabels:
app: wordpress
template:
metadata:
labels:
app: wordpress
spec:
containers:
- name: wordpress
image: wordpress
env:
- name: WORDPRESS_DB_HOST
value: "xxx.xxx.xxx.xxx:30306"
- name: WORDPRESS_DB_USER
value: "user1"
- name: WORDPRESS_DB_PASSWORD
value: "password1"
- name: WORDPRESS_DB_NAME
value: "mydb"
ports:
- containerPort: 80
Deployment 1つと、Service 1つ、環境変数の指定も不要で本シリーズで紹介する 30 個の中でも指折りにシンプルな YAML ファイルです。一応解説を加えておきます。アプリケーションそのものは 80 番ポートで動作するように作られているため、NodePort 30080 番を指定して、外部からは 30080 番ポートでアクセスできるようにしています(NodePort として指定可能な番号の範囲は 30000 ~ 32767 です、指定しない場合は空いている番号がランダムに割り振られます)。また ReplicaSet は1つだけで作りました。
デプロイしたコンテナイメージを削除する場合はデプロイ時に使った YAML ファイルを再度使って、以下のコマンドを実行します。不要であれば削除しておきましょう:
$ kubectl delete -f wordpress.yaml
$ kubectl delete -f mysql.yaml
【紹介したイメージ】
https://hub.docker.com/_/wordpress
【紹介記録】
ついに 30 日間 30 イメージ紹介を達成しました!
| Day | カテゴリー | デプロイ内容 |
|---|---|---|
| 0 | 準備 | 準備作業 |
| 1 | ウェブサーバー | hostname |
| 2 | Apache HTTP | |
| 3 | Nginx | |
| 4 | Tomcat | |
| 5 | Websphere Liberty | |
| 6 | データベース | MySQL |
| 7 | phpMyAdmin | |
| 8 | PostgreSQL | |
| 9 | pgAdmin4 | |
| 10 | MongoDB | |
| 11 | Mongo-Express | |
| 12 | Redis | |
| 13 | RedisCommander | |
| 14 | ElasticSearch | |
| 15 | Kibana | |
| 16 | CouchDB | |
| 17 | CouchBase | |
| 18 | HATOYA | |
| 19 | プログラミング | Node-RED |
| 20 | Scratch | |
| 21 | Eclipse Orion | |
| 22 | Swagger Editor | |
| 23 | R Studio | |
| 24 | Jenkins | |
| 25 | アプリケーション | FX |
| 26 | 2048 | |
| 27 | DOS Box | |
| 28 | VNC Server(Lubuntu) | |
| 29 | Drupal | |
| 30 | WordPress |