以前にも似たようなものを何度か作ったことがあったのですが、その最新改良作品です。 ツイッターでのつぶやき内容を元に自分の性格を分析して、その内容が時間とともにどのように変化していくか、を視覚化するというものです。
実際に自分の3月21日時点でのツイートを元にためしてみた結果がこちらです。なお現時点でスマホで表示する場合はレイアイトが最適化されていないため画面を横にして御覧ください:
https://personality-transition.mybluemix.net/transition/6f24cd50fa6f528cdd3162aadb716b03
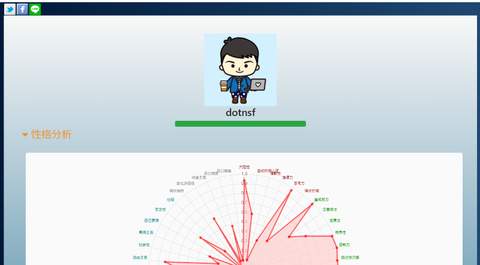
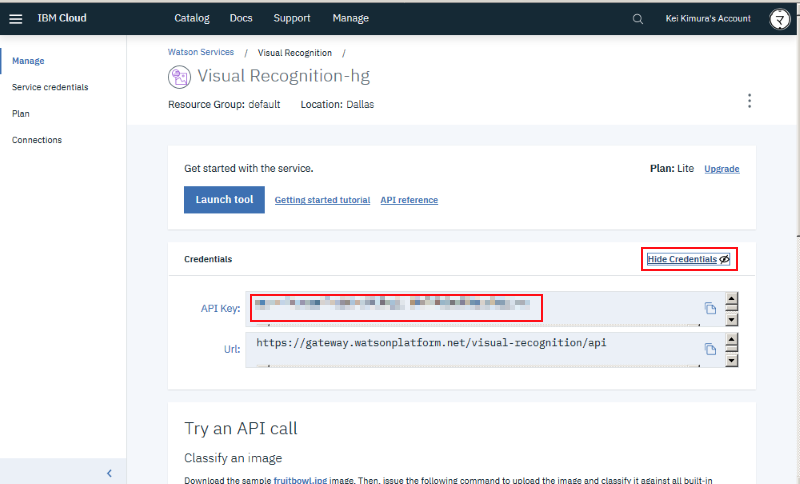
画面は最上部にシェア用のアイコンが並んだ下に性格を分析した本人の twitter アイコンと名前が表示され、その下に IBM Watson Personality Insights API を使った分析結果の「性格分析」と「消費行動動向」が表示されます(「消費行動動向は初期状態では省略表示されているので、内容を表示するには三角形部分をクリック(タップ)してください)。
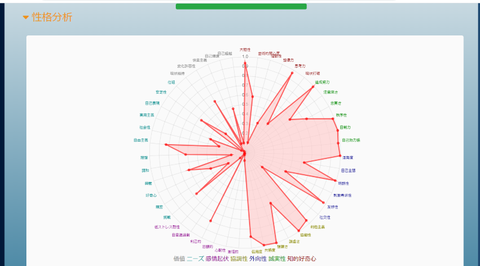
性格分析はビッグ5と呼ばれる5つの性格要素(知的好奇心、誠実性、外向性、協調性、感情起伏)に加え、ニーズ(共感を呼ぶ度合い)&価値(意思決定に影響を及ぼす要素)という7つのカテゴリを更に細分化した結果がレーダーチャートで表示されます:
また消費行動動向はその性格から結びつく消費行動の度合いが表示されます(色の濃い方がその要素が高く、薄い方が低い、という意味です):
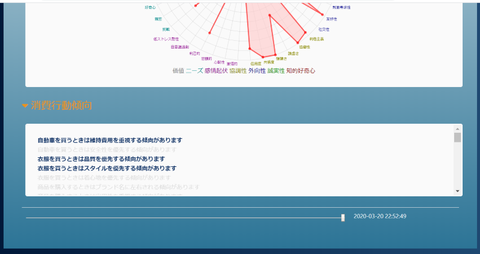
画面最下部にはスライダーが表示されています。初期状態では一番右にセットされていて、これは時間的に一番新しい分析結果が表示されていることを意味します:
このスライダーを左に移動していくと少しずつ前の(古い)性格分析結果や消費行動動向が表示されていきます。自分の性格が時間とともにどのように変化していったのか/変わらない要素は何か といった内容がわかるようになる、というものです:

このページの画面右上のリンクから皆さんのツイートでも試すことができます。興味ある方はぜひ挑戦してみて、よろしければその結果を SNS でシェアしてみてください:
https://personality-transition.mybluemix.net/transition/6f24cd50fa6f528cdd3162aadb716b03
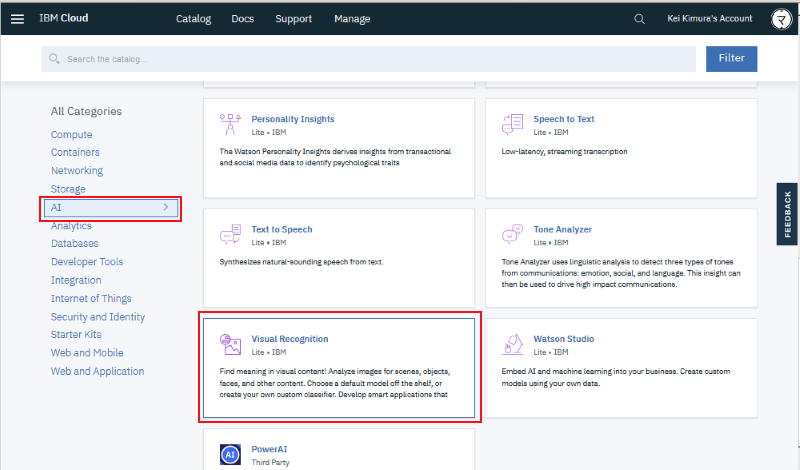
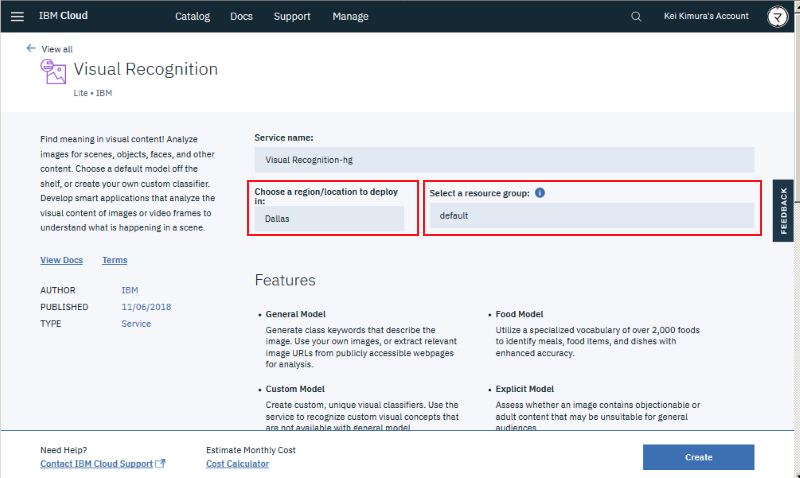
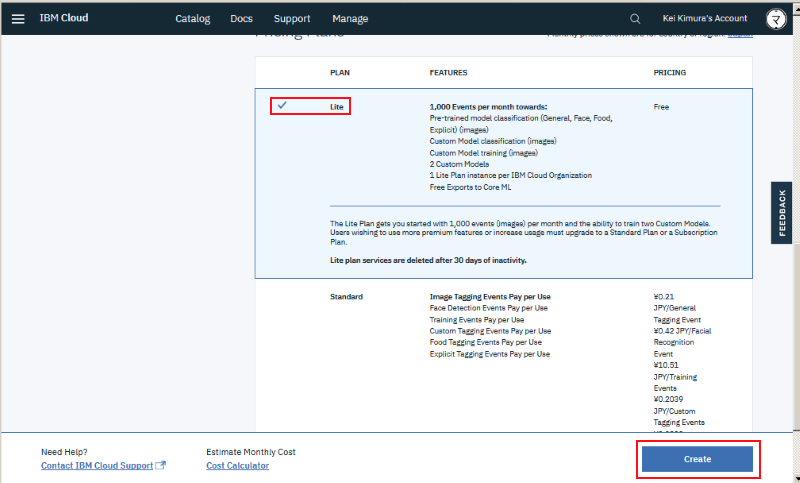
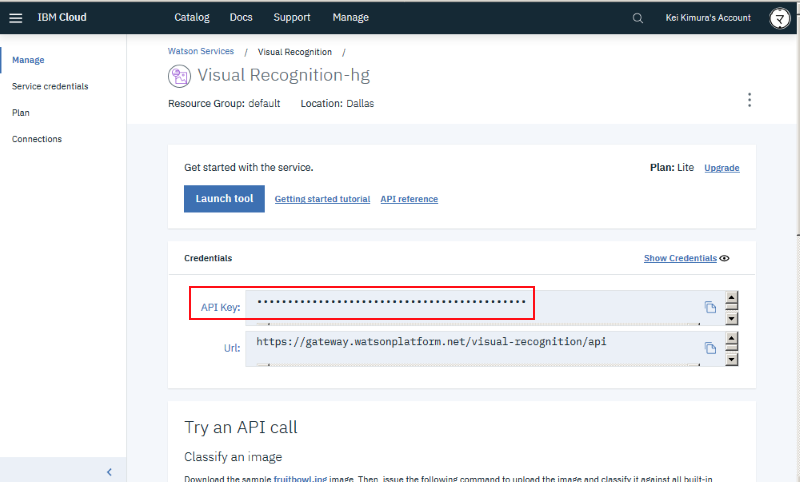
以下、このサービスを実現する上での技術要素の説明です。なおソースコードは公開していますので興味ある方はこちらも参照ください。なお IBM Cloud を使って動かす想定のコードとなっており、後述の IBM Watson やデータベース機能含めて無料のライトアカウントの範囲内でもデプロイ可能な内容となっています:
https://github.com/dotnsf/personality_transition
このサービスは Node.js で実装していますが、サービスを実現する上で利用しているライブラリは大きく3つです。1つ目は Twitter のログイン認可を実現するための OAuth 、2つ目は認可したユーザーのツイートを取得するための Twitter API 、そして3つ目は取得したツイート内容から性格分析を行う IBM Watson Personality Insights API です。
なお、ここで使っている IBM Watson Personality Insights は IBM Cloud から提供されている IBM Watson API の1つで、テキストの内容を使用単語レベルで分析し、そのテキストを記述した人の性格や、その性格毎の購買傾向を取得する、という便利な API です。日本語を含む5ヶ国語に対応しています。詳しくはこちらも参照ください:
https://www.ibm.com/watson/jp-ja/developercloud/personality-insights.html
おおまかな処理の流れとしては、まず OAuth2 で Twitter にログインしてもらうことで、そのユーザーの権限で Twitter が操作できるよう認可します。そして Twitter API でユーザーのタイムライン内容を取得します。 この時に直近の 200 ツイートを取得します。この 200 件のツイートを投稿時刻の順に 40 件ずつ5つのブロックにわけます。そして各ブロック毎のツイート内容をそれぞれまとめて IBM Watson Personality Insights API を使って性格分析を行います(つまり1回の処理で Twitter のタイムライン取得 API を1回、IBM Watson Personality Insights API を5回実行します)。このようにすることでツイートの内容を時間で区切って直近のものから少しずつ時間を遡りながら5回ぶんの性格分析を行い、その結果を上述のようにスライダーバーで時間ごとに表示/非表示を切り替えることで実現しています。
機能的にはこれだけでもできるのですが、このサービスでは「分析結果をシェア」できるようにしました。シェアするためには(シェアされた人はツイートを取得せずに分析結果を見ることができる必要があるため)分析した結果をデータベースに格納する必要があるため、データベースも併用しています(あくまで分析結果を保存するためのもので、ツイート内容は保存していません)。
また上述のような仕様であるため、仮に Twitter 上で非公開アカウントとしているアカウントに対しても(本人の権限でツイートを取得することになるので)性格分析を行ったり、その結果をシェアすることができます(公開許可されていない人や、そもそも Twitter アカウントを持っていない人でも分析結果を見ることができます)。ただしあくまで分析結果だけがシェアされるのであって、ツイート内容がシェアされるわけではない点はご安心を。
このデモサービスでは Twitter のツイートを元に性格分析を行っていますが、必ずしも分析元はツイートである必要はありません。1人の人が書いた文章であればよいので、メールなり、社内掲示板なりからテキストを取得することができるのであれば理論上は可能です。ただし1回の性格分析におけるテキストの単語数が少ないと充分な精度がでない結果となることも考えられます。ある程度の単語数が含まれるテキストを取得できる必要があります(このサービスでは上述のように 40 ツイートぶんのテキスト内容をひとまとめにして分析しています)。
また IBM Watson Personality Insights API の特徴でもあるのですが、単にテキスト内容とその単語傾向から性格を分析するだけでなく、購買行動への傾向と合わせた実行結果を得ることができます。つまりまだ何も買っていないユーザーに対してでも、その購買傾向を調べた上でレコメンドを出したり、特定興味分野の広告を出したりする、といった使い方にも応用ができるもので、特に今回のデモではその時間変化にも着目できるようにしています。応用の幅が非常に大きな API であると考えていて、その一部が伝わればいいと思っています。
実際に自分の3月21日時点でのツイートを元にためしてみた結果がこちらです。なお現時点でスマホで表示する場合はレイアイトが最適化されていないため画面を横にして御覧ください:
https://personality-transition.mybluemix.net/transition/6f24cd50fa6f528cdd3162aadb716b03

画面は最上部にシェア用のアイコンが並んだ下に性格を分析した本人の twitter アイコンと名前が表示され、その下に IBM Watson Personality Insights API を使った分析結果の「性格分析」と「消費行動動向」が表示されます(「消費行動動向は初期状態では省略表示されているので、内容を表示するには三角形部分をクリック(タップ)してください)。
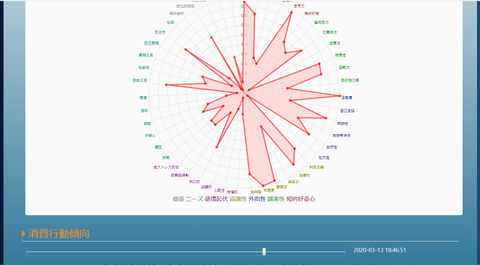
性格分析はビッグ5と呼ばれる5つの性格要素(知的好奇心、誠実性、外向性、協調性、感情起伏)に加え、ニーズ(共感を呼ぶ度合い)&価値(意思決定に影響を及ぼす要素)という7つのカテゴリを更に細分化した結果がレーダーチャートで表示されます:

また消費行動動向はその性格から結びつく消費行動の度合いが表示されます(色の濃い方がその要素が高く、薄い方が低い、という意味です):
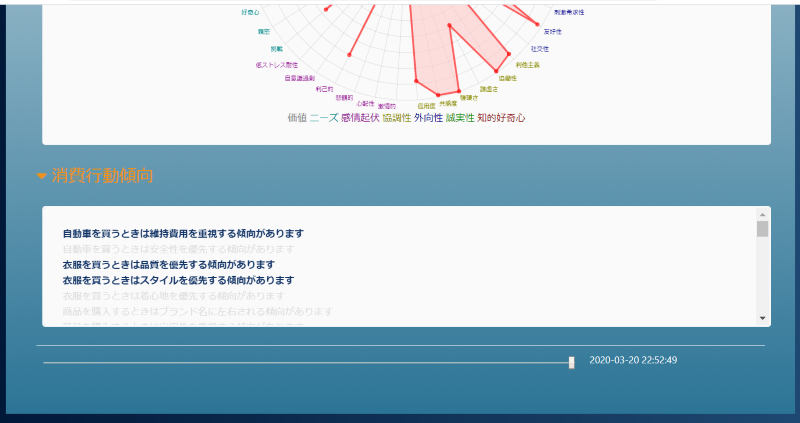
画面最下部にはスライダーが表示されています。初期状態では一番右にセットされていて、これは時間的に一番新しい分析結果が表示されていることを意味します:

このスライダーを左に移動していくと少しずつ前の(古い)性格分析結果や消費行動動向が表示されていきます。自分の性格が時間とともにどのように変化していったのか/変わらない要素は何か といった内容がわかるようになる、というものです:

このページの画面右上のリンクから皆さんのツイートでも試すことができます。興味ある方はぜひ挑戦してみて、よろしければその結果を SNS でシェアしてみてください:
https://personality-transition.mybluemix.net/transition/6f24cd50fa6f528cdd3162aadb716b03
以下、このサービスを実現する上での技術要素の説明です。なおソースコードは公開していますので興味ある方はこちらも参照ください。なお IBM Cloud を使って動かす想定のコードとなっており、後述の IBM Watson やデータベース機能含めて無料のライトアカウントの範囲内でもデプロイ可能な内容となっています:
https://github.com/dotnsf/personality_transition
このサービスは Node.js で実装していますが、サービスを実現する上で利用しているライブラリは大きく3つです。1つ目は Twitter のログイン認可を実現するための OAuth 、2つ目は認可したユーザーのツイートを取得するための Twitter API 、そして3つ目は取得したツイート内容から性格分析を行う IBM Watson Personality Insights API です。
なお、ここで使っている IBM Watson Personality Insights は IBM Cloud から提供されている IBM Watson API の1つで、テキストの内容を使用単語レベルで分析し、そのテキストを記述した人の性格や、その性格毎の購買傾向を取得する、という便利な API です。日本語を含む5ヶ国語に対応しています。詳しくはこちらも参照ください:
https://www.ibm.com/watson/jp-ja/developercloud/personality-insights.html
おおまかな処理の流れとしては、まず OAuth2 で Twitter にログインしてもらうことで、そのユーザーの権限で Twitter が操作できるよう認可します。そして Twitter API でユーザーのタイムライン内容を取得します。 この時に直近の 200 ツイートを取得します。この 200 件のツイートを投稿時刻の順に 40 件ずつ5つのブロックにわけます。そして各ブロック毎のツイート内容をそれぞれまとめて IBM Watson Personality Insights API を使って性格分析を行います(つまり1回の処理で Twitter のタイムライン取得 API を1回、IBM Watson Personality Insights API を5回実行します)。このようにすることでツイートの内容を時間で区切って直近のものから少しずつ時間を遡りながら5回ぶんの性格分析を行い、その結果を上述のようにスライダーバーで時間ごとに表示/非表示を切り替えることで実現しています。
機能的にはこれだけでもできるのですが、このサービスでは「分析結果をシェア」できるようにしました。シェアするためには(シェアされた人はツイートを取得せずに分析結果を見ることができる必要があるため)分析した結果をデータベースに格納する必要があるため、データベースも併用しています(あくまで分析結果を保存するためのもので、ツイート内容は保存していません)。
また上述のような仕様であるため、仮に Twitter 上で非公開アカウントとしているアカウントに対しても(本人の権限でツイートを取得することになるので)性格分析を行ったり、その結果をシェアすることができます(公開許可されていない人や、そもそも Twitter アカウントを持っていない人でも分析結果を見ることができます)。ただしあくまで分析結果だけがシェアされるのであって、ツイート内容がシェアされるわけではない点はご安心を。
このデモサービスでは Twitter のツイートを元に性格分析を行っていますが、必ずしも分析元はツイートである必要はありません。1人の人が書いた文章であればよいので、メールなり、社内掲示板なりからテキストを取得することができるのであれば理論上は可能です。ただし1回の性格分析におけるテキストの単語数が少ないと充分な精度がでない結果となることも考えられます。ある程度の単語数が含まれるテキストを取得できる必要があります(このサービスでは上述のように 40 ツイートぶんのテキスト内容をひとまとめにして分析しています)。
また IBM Watson Personality Insights API の特徴でもあるのですが、単にテキスト内容とその単語傾向から性格を分析するだけでなく、購買行動への傾向と合わせた実行結果を得ることができます。つまりまだ何も買っていないユーザーに対してでも、その購買傾向を調べた上でレコメンドを出したり、特定興味分野の広告を出したりする、といった使い方にも応用ができるもので、特に今回のデモではその時間変化にも着目できるようにしています。応用の幅が非常に大きな API であると考えていて、その一部が伝わればいいと思っています。