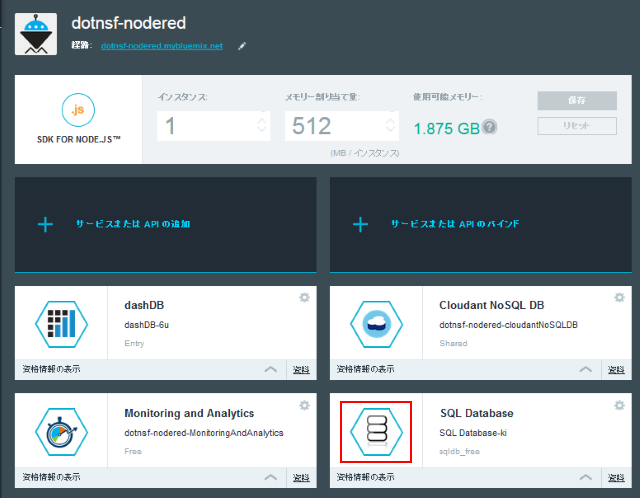
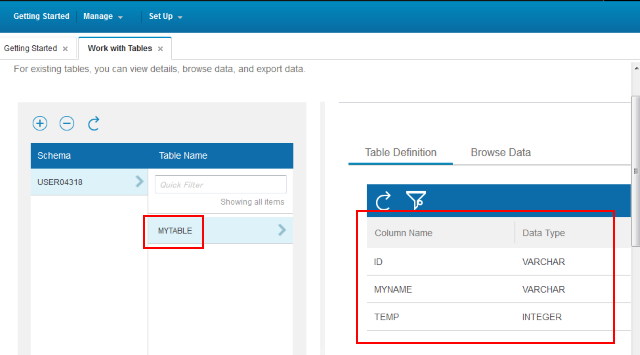
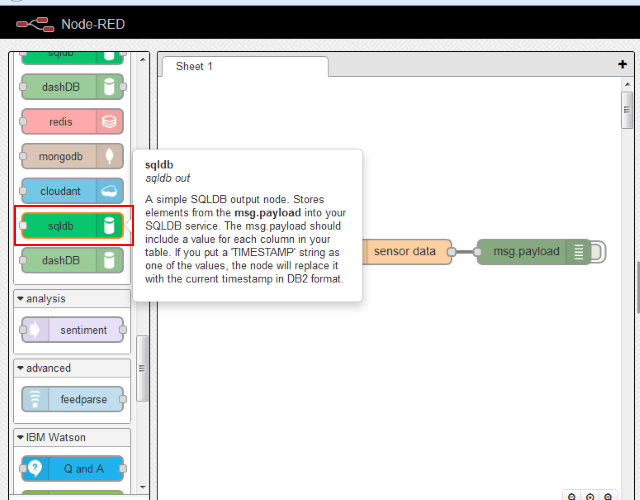
StrongLoop の LoopBack を使うと、データベースのモデルを定義するだけで CRUD の REST API を生成し、OpenAPI(Swagger) スタイルのドキュメントと併せて簡単に公開できます。この辺りについては以前のブログエントリを参照してください:
CentOS に StrongLoop をインストールする
ところで、LoopBack を使って公開された API にはパラメータで挙動を指定できるものもあります。例えばモデルの一覧を取得する GET リクエストでは一覧を絞り込むためのクエリーを指定したり、取得結果の数やオフセットを指定することも可能です:

そのための方法を紹介します。例えば items というテーブルに対して LoopBack で CRUD の API を作成したと仮定します。items の一覧を取得するには以下の様な URL に対する HTTP リクエストを GET で実行することになります(XX.XX.XX.XX は LoopBack が動いているサーバー):
さて、一覧の検索条件(例えば id < 100)を指定する場合、SQL ではこのように指定することになります:
この条件を指定して上記の HTTP GET リクエストを実行するには、つまり id < 100 のものだけの一覧を API で取得するには、以下の様なパラメータを指定して実行します:
filter という名前に [where] 句が指定され、更に条件である [id] が [lt] (Less Than) で 100 である、という条件が指定されていることになります。
一方、一覧の検索結果の取得数(例えば10件)を指定する場合、SQL(MySQL) ではこのように指定します:
この条件を指定して HTTP GET リクエストを実行するには、以下の様なパラメータを指定して実行します:
filter という名前に [limit] 句が指定され、その値が 10 である、という条件が指定されていることになります。なんとなくコツが分かってきましたか?
ちなみに一覧の検索結果の取得数を 50 件目からの 10 件、とするには SQL(MySQL) ではこのように指定します:
limit 句を指定し、オフセットが 0 以外の場合は limit 数の前にオフセット数を指定します。これを API のパラメータで指定するには以下のようにします:
クエリーや結果取得の条件は同時に指定することができます。例えば「 id < 100 のものをオフセット 50 で10 件取得」するのであれば、API ではこのように指定します:
filter の使い方、なんとなくコツがわかってきましたか? 使っているデータベースの種類は何で、そのデータベースでは SQL ではどういった指定になるか、をイメージできるとわかりやすいです。
このパラメータに関する API ドキュメントはこちら:
https://docs.strongloop.com/display/public/LB/Where+filter
CentOS に StrongLoop をインストールする
ところで、LoopBack を使って公開された API にはパラメータで挙動を指定できるものもあります。例えばモデルの一覧を取得する GET リクエストでは一覧を絞り込むためのクエリーを指定したり、取得結果の数やオフセットを指定することも可能です:
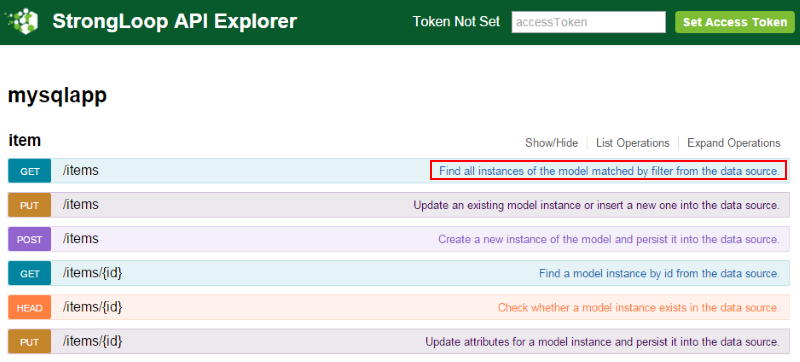
そのための方法を紹介します。例えば items というテーブルに対して LoopBack で CRUD の API を作成したと仮定します。items の一覧を取得するには以下の様な URL に対する HTTP リクエストを GET で実行することになります(XX.XX.XX.XX は LoopBack が動いているサーバー):
http://XX.XX.XX.XX/api/items/
さて、一覧の検索条件(例えば id < 100)を指定する場合、SQL ではこのように指定することになります:
> select * from items where id < 100;
この条件を指定して上記の HTTP GET リクエストを実行するには、つまり id < 100 のものだけの一覧を API で取得するには、以下の様なパラメータを指定して実行します:
http://XX.XX.XX.XX/api/items?filter[where][id][lt]=100
filter という名前に [where] 句が指定され、更に条件である [id] が [lt] (Less Than) で 100 である、という条件が指定されていることになります。
一方、一覧の検索結果の取得数(例えば10件)を指定する場合、SQL(MySQL) ではこのように指定します:
> select * from items limit 10;
この条件を指定して HTTP GET リクエストを実行するには、以下の様なパラメータを指定して実行します:
http://XX.XX.XX.XX/api/items?filter[limit]=10
filter という名前に [limit] 句が指定され、その値が 10 である、という条件が指定されていることになります。なんとなくコツが分かってきましたか?
ちなみに一覧の検索結果の取得数を 50 件目からの 10 件、とするには SQL(MySQL) ではこのように指定します:
> select * from items limit 50, 10;limit 句を指定し、オフセットが 0 以外の場合は limit 数の前にオフセット数を指定します。これを API のパラメータで指定するには以下のようにします:
http://XX.XX.XX.XX/api/items?filter[limit]=10&filter[offset]=50
クエリーや結果取得の条件は同時に指定することができます。例えば「 id < 100 のものをオフセット 50 で10 件取得」するのであれば、API ではこのように指定します:
http://XX.XX.XX.XX/api/items?filter[where][id][lt]=100&filter[limit]=10&filter[offset]=50
filter の使い方、なんとなくコツがわかってきましたか? 使っているデータベースの種類は何で、そのデータベースでは SQL ではどういった指定になるか、をイメージできるとわかりやすいです。
このパラメータに関する API ドキュメントはこちら:
https://docs.strongloop.com/display/public/LB/Where+filter