Tips 的な小ネタです。
Node.js + Express によるウェブアプリケーションコードの中で、何らかの URL への GET リクエスト(POST とかでもいいですが、処理内容は GET の時と同じなので GET で考えることにします)を受けて処理している時の、アクセス時のフル URL をサーバー側で知る方法です。 なお、ここでの「フル URL 」とは、プロトコル+ホスト名+(デフォルトと異なる場合は)ポート番号+アクセスパス+実行時のURLパラメータ のこととします。
この値はクライアント側の JavaScript を使えば windows.location オブジェクトを参照することで取得できます。ただこちらはあまり意味がないというか、アクセスしたユーザーは自分のブラウザのアドレス欄を見れば URL を確認できるのでわざわざ別途必要になるケースが珍しいはずです。このクライアントサイドでの話ではなく、サーバーサイドの処理内で知る方法、という意味です。
結論としては以下のようなコードで取得することが可能です:
まずルーティングのパス定義部分を '/*' としています。これによってルートパス以下のすべてのパスへの GET リクエストをこのハンドラが受け持つ、と宣言します。
肝心のフル URL ですが、このハンドラ実行時のパラメーター: req(リクエストオブジェクト)を使って、以下のように求めることができます:
var url = req.protocol + '://' + req.get( 'host' ) + req.originalUrl;
req.protocol にはプロトコル("http" または "https")、req.get( 'host' ) でポート番号まで含めたアクセス時のホスト名、そして req.originalUrl にはアクセス時のフルパスが URL パラメータまで含めた形で取得できます。これらをつなぎ合わせることでアクセス時のフル URL が取得できるので、これをレスポンスで返す、という処理をしています。
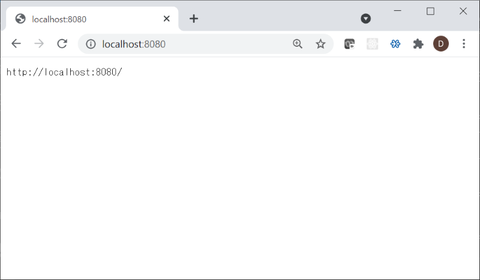
試しに実行していくつかの URL パターンでアクセスしてみた所、以下のようにいずれも期待通りの結果になりました:
(http://localhost:8080/)
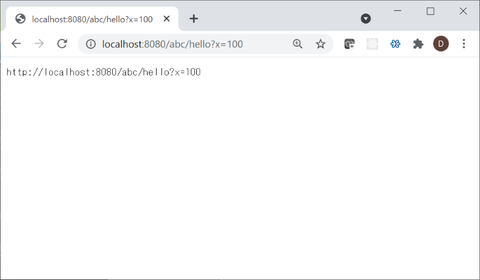
(http://localhost:8080/abc/hello?x=100)
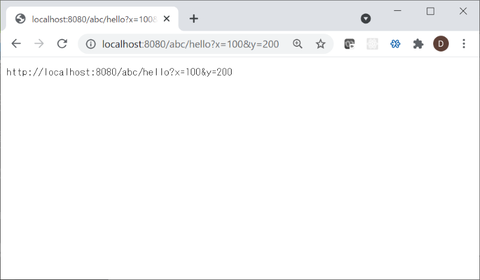
(http://localhost:8080/abc/hello?x=100&y=200)
1つの環境で複数のサーバー名を持って稼働するサーバーの場合に、「何というホスト名でアクセスされているのか」をサーバー側からも知ることができる、という情報でした。
なおこのアプリケーションのソースコードはこちらで公開しています:
https://github.com/dotnsf/access_url
どれだけ需要があるかわかりませんが、docker イメージ(dotnsf/access-url)の形で以下からも公開しています:
https://hub.docker.com/r/dotnsf/access_url
利用可能な Kubernetes クラスタ環境(と接続設定などが済んだ kubectl コマンド)があれば、以下の手順でコマンドを実行することで Deployment と(spec.type = "NodePort" の) Service を作成できます:
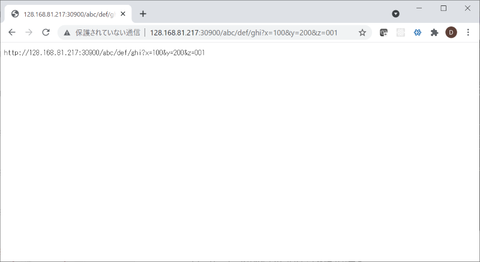
IBM Cloud の無料版 IKS(IBM Kubernetes Services) で、上記コマンドを実行して作成したアプリケーションにアクセスした時の様子が以下になります。アクセスした URL が正しくサーバーサイドで取得できている様子が確認できます:
最後に余談を。上述のクライアントサイド JavaScript による(window.location オブジェクトを用いた)取得方法との取得できる情報の違いについて補足します。
クライアントサイドで取得する場合、サーバーサイドで取得できない情報が1つ取得できます。それが「ハッシュ」と呼ばれる情報で例えば、
http://xxx.xxx.xxx.xxx/abc/hello?x=1&y=2#here
という URL アドレスの最後の "#here" 部分の情報です。
この情報はクライアントサイドであれば window.location.search を参照することで取得することが可能ですが、サーバーサイドでは取得する方法がありません。ただハッシュ情報はクライアントサイドで(HTML 内の特定位置を参照するなど)利用するためのものであって、サーバーサイドで生成する情報としてはハッシュによる差異はありません。要はサーバーサイドでは意味のない情報であるためサーバー側では取得できなくなっている、ものと思われます。
Node.js + Express によるウェブアプリケーションコードの中で、何らかの URL への GET リクエスト(POST とかでもいいですが、処理内容は GET の時と同じなので GET で考えることにします)を受けて処理している時の、アクセス時のフル URL をサーバー側で知る方法です。 なお、ここでの「フル URL 」とは、プロトコル+ホスト名+(デフォルトと異なる場合は)ポート番号+アクセスパス+実行時のURLパラメータ のこととします。
この値はクライアント側の JavaScript を使えば windows.location オブジェクトを参照することで取得できます。ただこちらはあまり意味がないというか、アクセスしたユーザーは自分のブラウザのアドレス欄を見れば URL を確認できるのでわざわざ別途必要になるケースが珍しいはずです。このクライアントサイドでの話ではなく、サーバーサイドの処理内で知る方法、という意味です。
結論としては以下のようなコードで取得することが可能です:
//. app.js
var express = require( 'express' ),
app = express();
app.get( '/*', function( req, res ){
res.contentType( 'text/plain; charset=utf-8' );
var url = req.protocol + '://' + req.get( 'host' ) + req.originalUrl;
res.write( url );
res.end();
});
var port = process.env.PORT || 8080;
app.listen( port );
console.log( "server starting on " + port + " ..." );
まずルーティングのパス定義部分を '/*' としています。これによってルートパス以下のすべてのパスへの GET リクエストをこのハンドラが受け持つ、と宣言します。
肝心のフル URL ですが、このハンドラ実行時のパラメーター: req(リクエストオブジェクト)を使って、以下のように求めることができます:
var url = req.protocol + '://' + req.get( 'host' ) + req.originalUrl;
req.protocol にはプロトコル("http" または "https")、req.get( 'host' ) でポート番号まで含めたアクセス時のホスト名、そして req.originalUrl にはアクセス時のフルパスが URL パラメータまで含めた形で取得できます。これらをつなぎ合わせることでアクセス時のフル URL が取得できるので、これをレスポンスで返す、という処理をしています。
試しに実行していくつかの URL パターンでアクセスしてみた所、以下のようにいずれも期待通りの結果になりました:
(http://localhost:8080/)

(http://localhost:8080/abc/hello?x=100)

(http://localhost:8080/abc/hello?x=100&y=200)

1つの環境で複数のサーバー名を持って稼働するサーバーの場合に、「何というホスト名でアクセスされているのか」をサーバー側からも知ることができる、という情報でした。
なおこのアプリケーションのソースコードはこちらで公開しています:
https://github.com/dotnsf/access_url
どれだけ需要があるかわかりませんが、docker イメージ(dotnsf/access-url)の形で以下からも公開しています:
https://hub.docker.com/r/dotnsf/access_url
利用可能な Kubernetes クラスタ環境(と接続設定などが済んだ kubectl コマンド)があれば、以下の手順でコマンドを実行することで Deployment と(spec.type = "NodePort" の) Service を作成できます:
$ git clone https://github.com/dotnsf/access_url $ cd access_url $ kubectl -f yaml/app_deployment.yaml
IBM Cloud の無料版 IKS(IBM Kubernetes Services) で、上記コマンドを実行して作成したアプリケーションにアクセスした時の様子が以下になります。アクセスした URL が正しくサーバーサイドで取得できている様子が確認できます:

最後に余談を。上述のクライアントサイド JavaScript による(window.location オブジェクトを用いた)取得方法との取得できる情報の違いについて補足します。
クライアントサイドで取得する場合、サーバーサイドで取得できない情報が1つ取得できます。それが「ハッシュ」と呼ばれる情報で例えば、
http://xxx.xxx.xxx.xxx/abc/hello?x=1&y=2#here
という URL アドレスの最後の "#here" 部分の情報です。
この情報はクライアントサイドであれば window.location.search を参照することで取得することが可能ですが、サーバーサイドでは取得する方法がありません。ただハッシュ情報はクライアントサイドで(HTML 内の特定位置を参照するなど)利用するためのものであって、サーバーサイドで生成する情報としてはハッシュによる差異はありません。要はサーバーサイドでは意味のない情報であるためサーバー側では取得できなくなっている、ものと思われます。