ラズパイ(ラズベリーパイ)上で検索エンジンである ElasticSearch が動くことがわかったので、自分も試してみました:
まず、ElasticSearch そのものにラズパイネイティブ版が存在しているわけではありません。 ElasticSearch は Java アプリケーションなので実行には Java が必要であり、Java が有効な環境であれば理論上は動きます。というわけで最初にラズパイに JDK 8 を導入します(導入済みであれば、ここは読み飛ばしても可)。
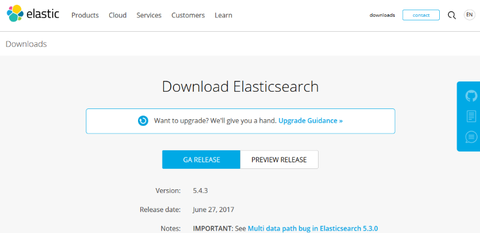
Java が使えるようになったので改めて ElasticSearch を導入します。ダウンロードページで確認すると、この記事を書いている 2017/Jul/06 時点での最新バージョンは 5.4.3 でした:
これをラズパイ上にダウンロードして展開します:
さて、他のプラットフォームだとこのまま実行してもいいのですが、ラズパイの場合はシステムスペックの問題でデフォルトの設定のままだとメモリ不足になりやすいという問題があります。そこで実行前にメモリの設定を変更しておきます。22 行目と 23 行目(か、そのあたり)で、"-Xms2g" と "-Xmx2g" という指定がされており、これによって ElasticSearch に 2GB のメモリを使うよう指定されています。ここを以下の赤字のように書き換えて、メモリ使用量を 256MB にするよう変更します:
これでメモリの問題は解決した(はず)なので、改めて ElasticSearch を起動します:
いくつかの警告メッセージが表示されますが、ラズパイ上で ElasticSearch 5.4.3 が起動しています。確認のため、同じマシンから curl でアクセスしてみましょう:
↑こんな感じのメッセージが表示されれば成功です。なお、ElasticSearch を終了するには実行中の端末で Ctrl+C を入力します:
実はいま、個人的にはラズパイを開発環境として使う機会がそれなりにあります(ラズパイにリモートログインして vi でガシガシ、という感じ)。そのローカルシステム内に ElasticSearch 環境まで構築できる時代になったとは・・・今以上に開発がはかどりますね。

まず、ElasticSearch そのものにラズパイネイティブ版が存在しているわけではありません。 ElasticSearch は Java アプリケーションなので実行には Java が必要であり、Java が有効な環境であれば理論上は動きます。というわけで最初にラズパイに JDK 8 を導入します(導入済みであれば、ここは読み飛ばしても可)。
$ sudo apt-get install oracle-java8-jdk
$ java -version
Java(TM) SE Runtime Environment (build 1.8.0_65-b17)
Java HotSpot(TM) Client VM (build 25.65-b01, mixed mode)
Java が使えるようになったので改めて ElasticSearch を導入します。ダウンロードページで確認すると、この記事を書いている 2017/Jul/06 時点での最新バージョンは 5.4.3 でした:

これをラズパイ上にダウンロードして展開します:
$ cd ~ $ wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-5.4.3.zip $ unzip elasticsearch-5.4.3.zip $ rm elasticsearch-5.4.3.zip $ mv elasticsearch-5.4.3 elasticsearch $ cd elasticsearch
さて、他のプラットフォームだとこのまま実行してもいいのですが、ラズパイの場合はシステムスペックの問題でデフォルトの設定のままだとメモリ不足になりやすいという問題があります。そこで実行前にメモリの設定を変更しておきます。22 行目と 23 行目(か、そのあたり)で、"-Xms2g" と "-Xmx2g" という指定がされており、これによって ElasticSearch に 2GB のメモリを使うよう指定されています。ここを以下の赤字のように書き換えて、メモリ使用量を 256MB にするよう変更します:
$ vi config/jvm.options : : -Xms256m ← -Xms2g から変更 -Xmx256m ← -Xmx2g から変更 : :
これでメモリの問題は解決した(はず)なので、改めて ElasticSearch を起動します:
$ ./bin/elasticsearch
[2017-07-06T10:41:17,203][WARN ][o.e.b.Natives ] unable to load JNA native support library, native methods will be disabled. : : [2017-07-06T10:41:39,511][INFO ][o.e.h.n.Netty4HttpServerTransport] [lonXjYa] publish_address {127.0.0.1:9200}, bound_addresses {[::1]:9200}, {127.0.0.1:9200} [2017-07-06T10:41:39,537][INFO ][o.e.n.Node ] [lonXjYa] started [2017-07-06T10:41:39,579][INFO ][o.e.g.GatewayService ] [lonXjYa] recovered [0] indices into cluster_state
いくつかの警告メッセージが表示されますが、ラズパイ上で ElasticSearch 5.4.3 が起動しています。確認のため、同じマシンから curl でアクセスしてみましょう:
$ curl http://localhost:9200/
{
"name" : "lonXjYa",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "4hqvLhXQT0uqTaKOI02idg",
"version" : {
"number" : "5.4.3",
"build_hash" : "eed30a8",
"build_date" : "2017-06-22T00:34:03.743Z",
"build_snapshot" : false,
"lucene_version" : "6.5.1"
},
"tagline" : "You Know, for Search"
}
↑こんな感じのメッセージが表示されれば成功です。なお、ElasticSearch を終了するには実行中の端末で Ctrl+C を入力します:
:
:
[2017-07-06T10:41:39,537][INFO ][o.e.n.Node ] [lonXjYa] started
[2017-07-06T10:41:39,579][INFO ][o.e.g.GatewayService ] [lonXjYa] recovered [0] indices into cluster_state
^C[2017-07-06T10:52:09,484][INFO ][o.e.n.Node ] [lonXjYa] stopping ...
[2017-07-06T10:52:09,579][INFO ][o.e.n.Node ] [lonXjYa] stopped
[2017-07-06T10:52:09,581][INFO ][o.e.n.Node ] [lonXjYa] closing ...
[2017-07-06T10:52:09,668][INFO ][o.e.n.Node ] [lonXjYa] closed
$
実はいま、個人的にはラズパイを開発環境として使う機会がそれなりにあります(ラズパイにリモートログインして vi でガシガシ、という感じ)。そのローカルシステム内に ElasticSearch 環境まで構築できる時代になったとは・・・今以上に開発がはかどりますね。