Bonsai Elasticsearch はその名前の通り、高速多機能な検索エンジンである Elasticsearch による検索機能をダッシュボード機能も含めてマネージドサービスとして提供するプロバイダーです。日本語の情報が少ないせいか、技術記事含めて情報自体を見ることがあまりありませんでした。偉そうに言ってますが、自分も以下の件で興味を持つまでは存じ上げていませんでした:
Bonsai Elasticsearch は Salesforce から提供されている PaaS 環境である heroku のサードパーティサービスの1つでもあります。heroku 自体も無料で使える利用枠が提供されていて、また Bonsai Elasticsearch にも無料枠があるため、heroku を経由してサービスを申し込むと「検索エンジンの使えるアプリケーションを無料で開発・運用できる環境」を手に入れることができます。世に多くのクラウド環境はありますが、Elasticsearch が無料で使えるアプリケーション・サーバー環境、という時点でかなり珍しいといえます:
一方で、現実的に日本人を対象とするアプリケーションを考えると、検索機能は日本語検索ができなければあまり実用的とはいえません。英語のように単語と単語の間に明確なスペースが入って区切られるわけではない日本語は、テキスト内の単語と単語の区切りを見つける時点でかなりハードルが高く、そこから更に検索インデックスを作る必要があるためです。ここまでの機能がサポートされていないと検索エンジンとしては使いにくいのでした。 例えば自分で自分の(手元の)PC やサーバーに Elasticsearch をインストールした場合であれば、自分で更に日本語形態素解析機能を追加でインストールすればいいのですが、クラウドのマネージドサービスとして提供されている場合、そのような権限をもらえないことも多いため、サービスとして提供されている機能の中に多言語対応(日本語対応)が含まれていないといけない、という高めのハードルが設定されているのでした。
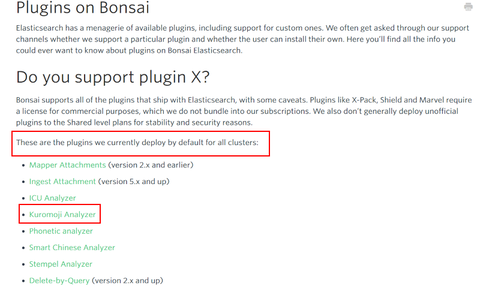
そんな中で見つけたこの Bonsai Elasticsearch 。ネットの日本語情報が少ないということは、日本語が使えないということかな・・・ と勝手に想像していました。 が、Bonsai のドキュメントを調べてみると Bonsai Elasticsearch に始めから導入されているプラグイン一覧の中に日本語形態素解析である "Kuromoji Analyzer" の文字を見つけました。あれ?これはもしかして期待できるやつ?:
https://docs.bonsai.io/article/135-plugins-on-bonsai
というわけで、実際に Bonsai Elasticsearch で日本語検索ができるかどうかを調べてみました。結論としてはどうやら使えそう(!!!)だと思ってます。以下はその際の記録です。
【調査に使ったシナリオ】
最初に迷ったのは「何を調べれば日本語検索ができるといえそうか」でした。日本語データを入れて、日本語で検索して、日本語のそれっぽいデータが返ってきたらいいのか?? というと、そうともいえないし・・・
で、今回は Elastic 社の日本語エンジニアリングブログから提供されていた『Elasticsearchで日本語のサジェストの機能を実装する』というエントリで紹介されていた方法が Bonsai Elasticsearch でできるかどうかを調べました。詳細はリンク先を確認していただきたいのですが、大まかな内容としては kuromoji を使う前提で日本語でのサジェスト機能を実装するためのインデックスおよびマッピングを作成し、日本語のデータを入れた上で検索して結果を見る、というものです。ここで紹介されているのは入力ミスまでを考慮した曖昧な検索を行うという内容で、この結果が期待通りになればそれはもう大丈夫でしょ、という判断です。
ちなみに同ページで紹介されている内容自体が日本語サジェストを実現するための考え方なども紹介されていて非常に有用でした。その上で、ここで紹介されていることと同じ内容が Bonsai Elasticsearch に対して行っても同じ結果になるか(Bonsai Elasticsearch で日本語形態素解析が使えれば同じ結果になるはず)、を試してみました:
https://www.elastic.co/jp/blog/implementing-japanese-autocomplete-suggestions-in-elasticsearch
【Bonsai Elasticsearch の準備】
まずは Bonsai Elasticsearch のインスタンスを準備します。自分の場合は heroku 経由でインスタンスを作成したので、その場合の手順を紹介します。
まず heroku で無料アカウントを作成し、クレジットカードを登録しておきます(無料版の Bonsai Elasticsearch を使いますが、そのためには heroku アカウントにクレジットカードの登録が必要です)。改めてブラウザで heroku にログインし、(必要であれば)アプリケーションを1つ作成した上でそのアプリケーションにアドオンとして紐付ける形で Bonsai Elasticsearch を追加します。アプリケーションを選択して、"Overview" タブから "Configure Add-ons" を選択します:
アドオンを選択する画面で検索ボックスに "Bonsai" と入力すると "Bonsai Elasticsearch" が見つかるのでこれを選択します:
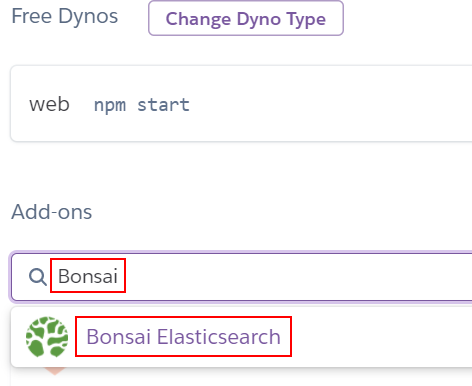
こんな感じの確認画面が表示されたら、無料プランの "Sandbox - Free" が選択されていることを確認して(これ以外は有料です) "Submit Order Form" ボタンをクリックします:
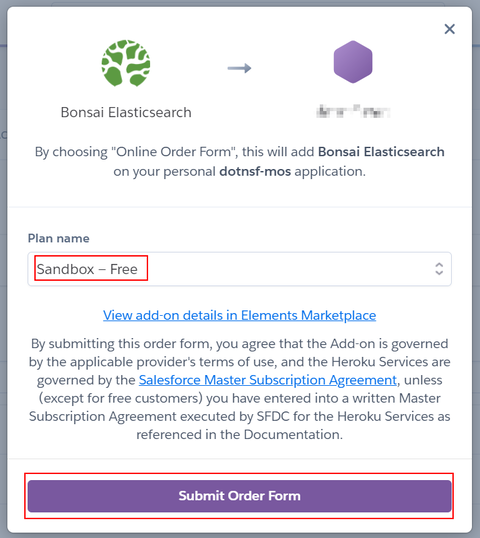
正しく処理されると、アプリケーションのアドオン一覧に "Bonsai Elasticsearch" が追加されます:
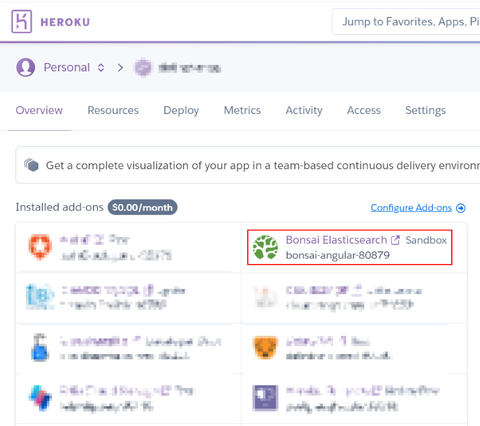
追加された Bonsai Elasticsearch にアクセスするための接続 URL を確認します。同アプリケーションの "Settings" タブから "Reveal Config Vars" ボタンをクリックします:
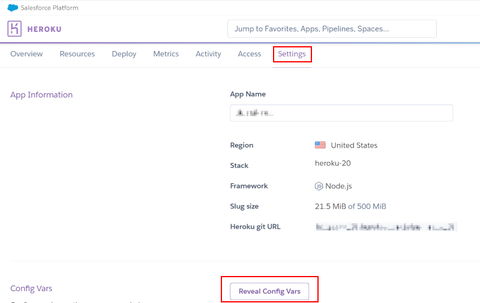
すると、このアプリケーションの動作時に設定される環境変数の一覧が表示されます。さきほど、Bonsai Elasticsearch を追加した際のオペレーションで "BONSAI_URL" という環境変数が設定されているはずです:
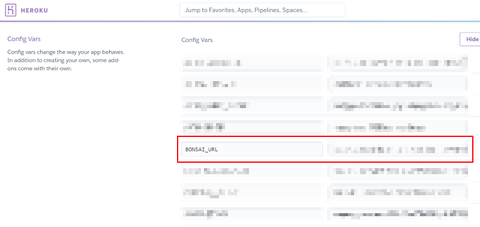
ここでコピーした BONSAI_URL の値は、このようなフォーマットのテキストになっているはずです:
https://username:password@xxxxxxxx.us-east-1.bonsaisearch.net:443
この値をこの後のインデックス作成やクエリー実行時に使うことになります。何度も使うことになるのでコピペできるよう、どこかに退避しておきましょう。
ここまで完了すれば Bonsai Elasticsearch の準備は環境です。
【Bonsai Elasticsearch に日本語インデックスと日本語データを作成して検索】
ここまでの準備ができれば Elastic 社の日本語エンジニアリングブログで紹介されていた、この内容を実際に試すことができるようになります:
https://www.elastic.co/jp/blog/implementing-japanese-autocomplete-suggestions-in-elasticsearch
ただ具体的なコマンド入力を考慮すると、このままだと少しわかりにくいため、この内容がもう少し試しやすくなるようなファイルやコマンド集(なんなら実行結果も含まれてますw)を作って公開しました。単に挙動や結果だけを確認したい人はこちらをダウンロードして使ってください:
https://github.com/dotnsf/bonsai_elasticsearch
以下に curl を使った具体的な手順とともに紹介します。日本語エンジニアリングブログによると、最初に kuromoji を使った日本語インデックスを作成する必要があります。上述でダウンロードしたファイルの中に含まれている my_suggest.json が日本語インデックスとマッピングを構成するファイルなので、以下の curl コマンドを実行してこれを Bonsai Elasticsearch に PUT します:
(https://username:password@xxxxxxxx.us-east-1.bonsaisearch.net:443 部分は先述の BONSAI_URL の値に置き換えて指定してください。以下同様)
次に検索対象となる日本語データをまとめてバルクアップロードします。データファイルは japanese.json です(厳密には JSON フォーマットではなく、複数の JSON が繋がっているフォーマットです。そのため後述のコマンドで特殊な Content-Type を指定する必要があります)。このファイルを以下の curl コマンドで Bonsai Elasticsearch に POST します:
(Content-Type の指定値が 'application/json' ではなく、'application/x-ndjson' となっている点に注意してください)
これで Bonsai Elasticsearch に日本語インデックスと日本語データが格納されました。これらが正しく日本語で検索できるかどうか(このブログの本来の目的でいえば、5種類の曖昧な日本語検索をしても同じ結果になるかどうか)を確認してみます。5種類の検索クエリーを5つのファイル(query1.json, query2.json, ..., query5.json)で用意したので、5回に分けてそれぞれを実行し、その結果を result1.json, result2.json, ..., result5.json に格納します:
ちなみにこれらの検索の内容ですが、「日本」という文字を多く含む日本語データがある程度格納されている状況下で、query1.json では「日本」を、query2.json では「にほn」を、query3.json では「にhん」を、query4.json では「にっほん」を、そして query5.json では「日本ん」を検索します。このように入力ミスまで考慮した曖昧な検索をしても同じ検索結果になるようなインデックスとマッピングを作る、という内容でした。実際に result1.json から result5.json まで見ると、検索結果はどれも一致しているはずです。
・・・というわけで、無料の Bonsai Elasticsearch (と導入済みの kuromoji)を使って日本語インデックスで日本語データを期待通りに検索できることがわかりました。こりゃ、いいモン見つけたかも!
Bonsai Elasticsearch は Salesforce から提供されている PaaS 環境である heroku のサードパーティサービスの1つでもあります。heroku 自体も無料で使える利用枠が提供されていて、また Bonsai Elasticsearch にも無料枠があるため、heroku を経由してサービスを申し込むと「検索エンジンの使えるアプリケーションを無料で開発・運用できる環境」を手に入れることができます。世に多くのクラウド環境はありますが、Elasticsearch が無料で使えるアプリケーション・サーバー環境、という時点でかなり珍しいといえます:

一方で、現実的に日本人を対象とするアプリケーションを考えると、検索機能は日本語検索ができなければあまり実用的とはいえません。英語のように単語と単語の間に明確なスペースが入って区切られるわけではない日本語は、テキスト内の単語と単語の区切りを見つける時点でかなりハードルが高く、そこから更に検索インデックスを作る必要があるためです。ここまでの機能がサポートされていないと検索エンジンとしては使いにくいのでした。 例えば自分で自分の(手元の)PC やサーバーに Elasticsearch をインストールした場合であれば、自分で更に日本語形態素解析機能を追加でインストールすればいいのですが、クラウドのマネージドサービスとして提供されている場合、そのような権限をもらえないことも多いため、サービスとして提供されている機能の中に多言語対応(日本語対応)が含まれていないといけない、という高めのハードルが設定されているのでした。
そんな中で見つけたこの Bonsai Elasticsearch 。ネットの日本語情報が少ないということは、日本語が使えないということかな・・・ と勝手に想像していました。 が、Bonsai のドキュメントを調べてみると Bonsai Elasticsearch に始めから導入されているプラグイン一覧の中に日本語形態素解析である "Kuromoji Analyzer" の文字を見つけました。あれ?これはもしかして期待できるやつ?:
https://docs.bonsai.io/article/135-plugins-on-bonsai

というわけで、実際に Bonsai Elasticsearch で日本語検索ができるかどうかを調べてみました。結論としてはどうやら使えそう(!!!)だと思ってます。以下はその際の記録です。
【調査に使ったシナリオ】
最初に迷ったのは「何を調べれば日本語検索ができるといえそうか」でした。日本語データを入れて、日本語で検索して、日本語のそれっぽいデータが返ってきたらいいのか?? というと、そうともいえないし・・・
で、今回は Elastic 社の日本語エンジニアリングブログから提供されていた『Elasticsearchで日本語のサジェストの機能を実装する』というエントリで紹介されていた方法が Bonsai Elasticsearch でできるかどうかを調べました。詳細はリンク先を確認していただきたいのですが、大まかな内容としては kuromoji を使う前提で日本語でのサジェスト機能を実装するためのインデックスおよびマッピングを作成し、日本語のデータを入れた上で検索して結果を見る、というものです。ここで紹介されているのは入力ミスまでを考慮した曖昧な検索を行うという内容で、この結果が期待通りになればそれはもう大丈夫でしょ、という判断です。
ちなみに同ページで紹介されている内容自体が日本語サジェストを実現するための考え方なども紹介されていて非常に有用でした。その上で、ここで紹介されていることと同じ内容が Bonsai Elasticsearch に対して行っても同じ結果になるか(Bonsai Elasticsearch で日本語形態素解析が使えれば同じ結果になるはず)、を試してみました:
https://www.elastic.co/jp/blog/implementing-japanese-autocomplete-suggestions-in-elasticsearch
【Bonsai Elasticsearch の準備】
まずは Bonsai Elasticsearch のインスタンスを準備します。自分の場合は heroku 経由でインスタンスを作成したので、その場合の手順を紹介します。
まず heroku で無料アカウントを作成し、クレジットカードを登録しておきます(無料版の Bonsai Elasticsearch を使いますが、そのためには heroku アカウントにクレジットカードの登録が必要です)。改めてブラウザで heroku にログインし、(必要であれば)アプリケーションを1つ作成した上でそのアプリケーションにアドオンとして紐付ける形で Bonsai Elasticsearch を追加します。アプリケーションを選択して、"Overview" タブから "Configure Add-ons" を選択します:
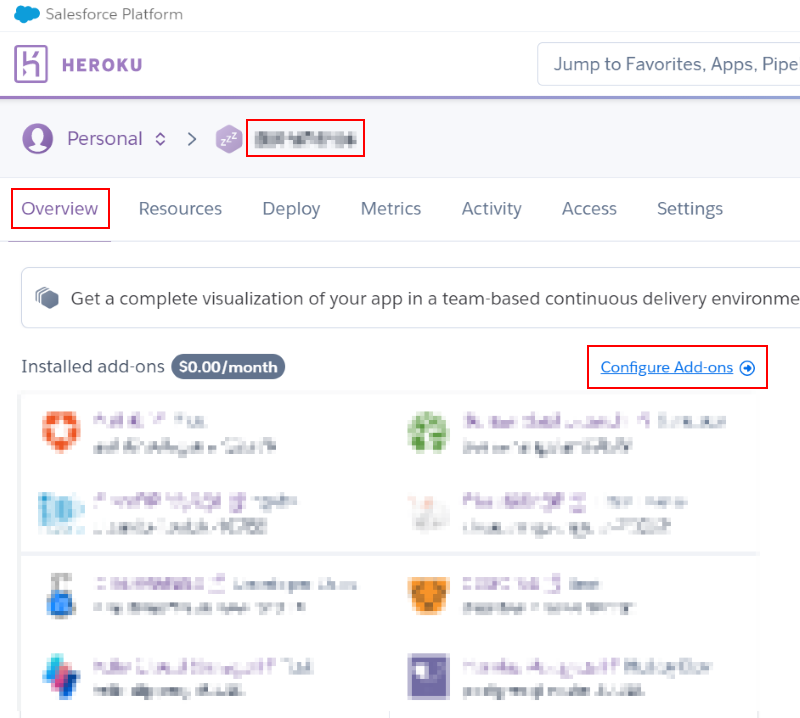
アドオンを選択する画面で検索ボックスに "Bonsai" と入力すると "Bonsai Elasticsearch" が見つかるのでこれを選択します:
こんな感じの確認画面が表示されたら、無料プランの "Sandbox - Free" が選択されていることを確認して(これ以外は有料です) "Submit Order Form" ボタンをクリックします:

正しく処理されると、アプリケーションのアドオン一覧に "Bonsai Elasticsearch" が追加されます:
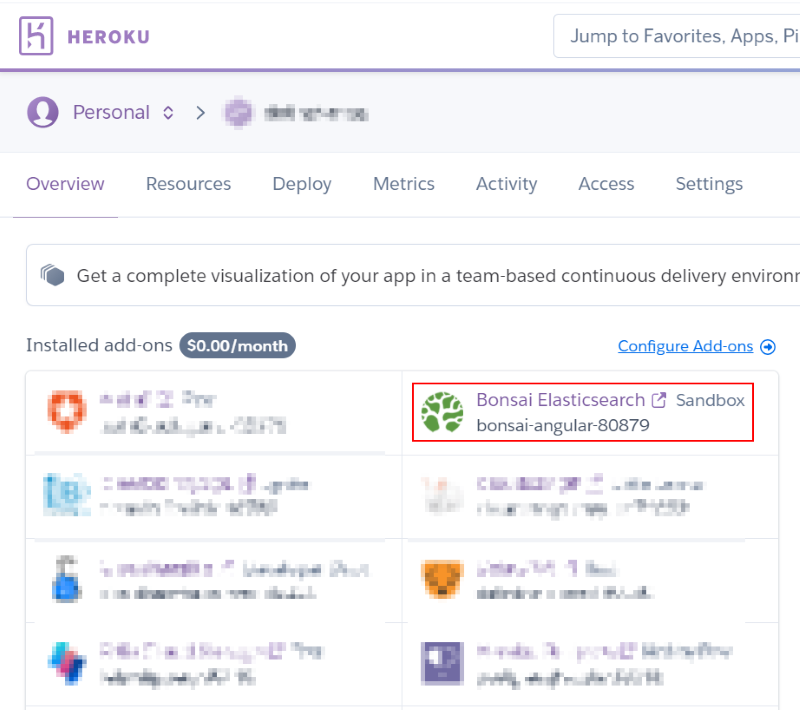
追加された Bonsai Elasticsearch にアクセスするための接続 URL を確認します。同アプリケーションの "Settings" タブから "Reveal Config Vars" ボタンをクリックします:

すると、このアプリケーションの動作時に設定される環境変数の一覧が表示されます。さきほど、Bonsai Elasticsearch を追加した際のオペレーションで "BONSAI_URL" という環境変数が設定されているはずです:

ここでコピーした BONSAI_URL の値は、このようなフォーマットのテキストになっているはずです:
https://username:password@xxxxxxxx.us-east-1.bonsaisearch.net:443
この値をこの後のインデックス作成やクエリー実行時に使うことになります。何度も使うことになるのでコピペできるよう、どこかに退避しておきましょう。
ここまで完了すれば Bonsai Elasticsearch の準備は環境です。
【Bonsai Elasticsearch に日本語インデックスと日本語データを作成して検索】
ここまでの準備ができれば Elastic 社の日本語エンジニアリングブログで紹介されていた、この内容を実際に試すことができるようになります:
https://www.elastic.co/jp/blog/implementing-japanese-autocomplete-suggestions-in-elasticsearch
ただ具体的なコマンド入力を考慮すると、このままだと少しわかりにくいため、この内容がもう少し試しやすくなるようなファイルやコマンド集(なんなら実行結果も含まれてますw)を作って公開しました。単に挙動や結果だけを確認したい人はこちらをダウンロードして使ってください:
https://github.com/dotnsf/bonsai_elasticsearch
以下に curl を使った具体的な手順とともに紹介します。日本語エンジニアリングブログによると、最初に kuromoji を使った日本語インデックスを作成する必要があります。上述でダウンロードしたファイルの中に含まれている my_suggest.json が日本語インデックスとマッピングを構成するファイルなので、以下の curl コマンドを実行してこれを Bonsai Elasticsearch に PUT します:
$ curl -XPUT https://username:password@xxxxxxxx.us-east-1.bonsaisearch.net:443/my_suggest -d @my_suggest.json -H 'Content-Type: application/json'
(https://username:password@xxxxxxxx.us-east-1.bonsaisearch.net:443 部分は先述の BONSAI_URL の値に置き換えて指定してください。以下同様)
次に検索対象となる日本語データをまとめてバルクアップロードします。データファイルは japanese.json です(厳密には JSON フォーマットではなく、複数の JSON が繋がっているフォーマットです。そのため後述のコマンドで特殊な Content-Type を指定する必要があります)。このファイルを以下の curl コマンドで Bonsai Elasticsearch に POST します:
$ curl -XPOST https://username:password@xxxxxxxx.us-east-1.bonsaisearch.net:443/my_suggest/_bulk --data-binary @japanese.json -H 'Content-Type: application/x-ndjson'
(Content-Type の指定値が 'application/json' ではなく、'application/x-ndjson' となっている点に注意してください)
これで Bonsai Elasticsearch に日本語インデックスと日本語データが格納されました。これらが正しく日本語で検索できるかどうか(このブログの本来の目的でいえば、5種類の曖昧な日本語検索をしても同じ結果になるかどうか)を確認してみます。5種類の検索クエリーを5つのファイル(query1.json, query2.json, ..., query5.json)で用意したので、5回に分けてそれぞれを実行し、その結果を result1.json, result2.json, ..., result5.json に格納します:
$ curl -XGET https://username:password@xxxxxxxx.us-east-1.bonsaisearch.net:443/my_suggest/_search -d @query1.json -H 'Content-Type: application/json' > result1.json $ curl -XGET https://username:password@xxxxxxxx.us-east-1.bonsaisearch.net:443/my_suggest/_search -d @query2.json -H 'Content-Type: application/json' > result2.json $ curl -XGET https://username:password@xxxxxxxx.us-east-1.bonsaisearch.net:443/my_suggest/_search -d @query3.json -H 'Content-Type: application/json' > result3.json $ curl -XGET https://username:password@xxxxxxxx.us-east-1.bonsaisearch.net:443/my_suggest/_search -d @query4.json -H 'Content-Type: application/json' > result4.json $ curl -XGET https://username:password@xxxxxxxx.us-east-1.bonsaisearch.net:443/my_suggest/_search -d @query5.json -H 'Content-Type: application/json' > result5.json
ちなみにこれらの検索の内容ですが、「日本」という文字を多く含む日本語データがある程度格納されている状況下で、query1.json では「日本」を、query2.json では「にほn」を、query3.json では「にhん」を、query4.json では「にっほん」を、そして query5.json では「日本ん」を検索します。このように入力ミスまで考慮した曖昧な検索をしても同じ検索結果になるようなインデックスとマッピングを作る、という内容でした。実際に result1.json から result5.json まで見ると、検索結果はどれも一致しているはずです。
・・・というわけで、無料の Bonsai Elasticsearch (と導入済みの kuromoji)を使って日本語インデックスで日本語データを期待通りに検索できることがわかりました。こりゃ、いいモン見つけたかも!

