StrongLoop の API プラットフォームにおける利用状況や接続先データソースをグラフィカルな UI で管理するツールが StrongLoop Arc です:
https://strongloop.com/node-js/arc/
StrongLoop (や LoopBack )の slc コマンドを導入済みの環境であればすぐに使うことができます。試しに LoopBack で API を作った時の環境を使って、StrongLoop Arc を利用してみます。LoopBack を導入する手順についてはこちらを参照ください:
CentOS に StrongLoop をインストールする
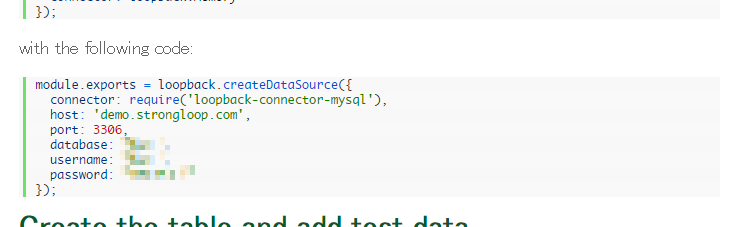
上記手順を行い、"myapp2" という名前で LoopBack アプリケーションが作られていると仮定します。この環境を使って、StrongLoop Arc を利用するには、アプリケーションフォルダに移動して、"slc arc" コマンドを実行します:
するとこんな感じで StrongLoop Arc が起動します。以下の例では 41241 番ポートで起動していますが、このポート番号は動的に変わるようです:

ではこの環境にウェブブラウザでアクセスしてみましょう。なお、StrongLoop Arc はリモートアクセスを許可していないので、この StrongLoop 環境を導入したマシンそのものにログインしてからウェブブラウザで http://localhost:XXXXX/ にアクセスする必要があります:
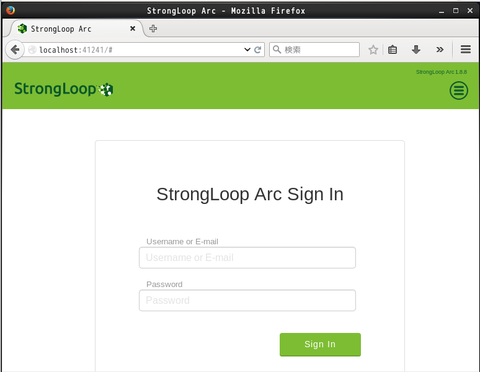
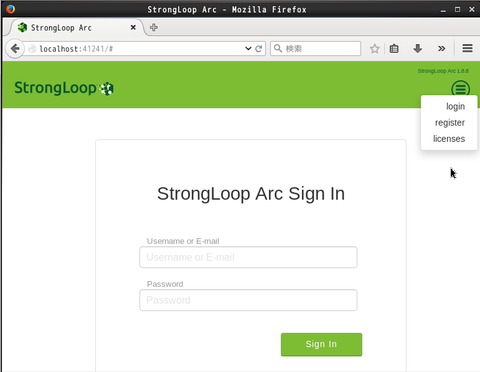
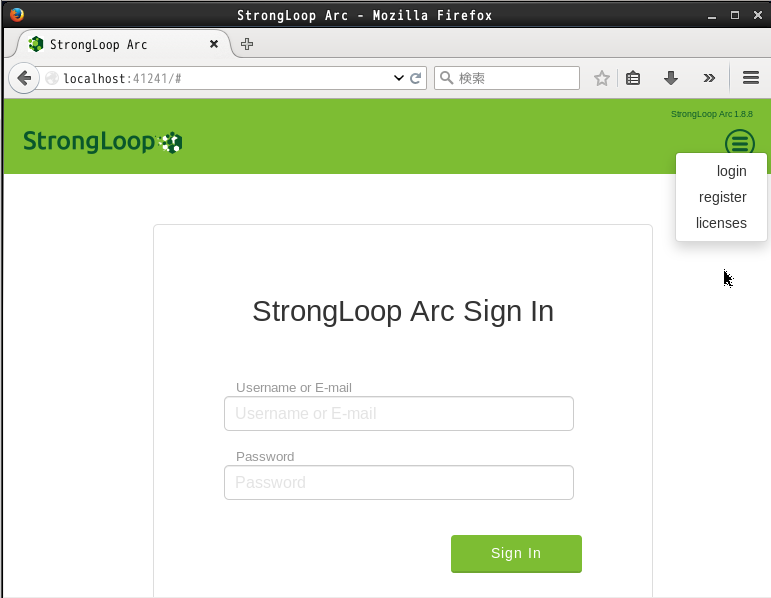
StrongLoop Arc を使うにはアカウントが必要です。まだお持ちでない場合は画面右上のハンバーガーメニューから "register" を選んで登録を行います:
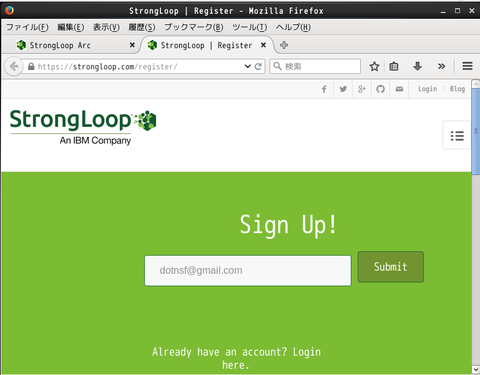
登録するユーザーのメールアドレスを指定して "Submit":
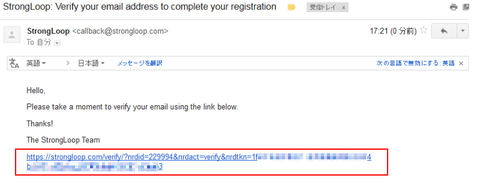
指定アドレスに StrongLoop からメールが届いたら、メール内のリンクをクリック:
で、ユーザー名やパスワードやら、残りの項目を登録します:
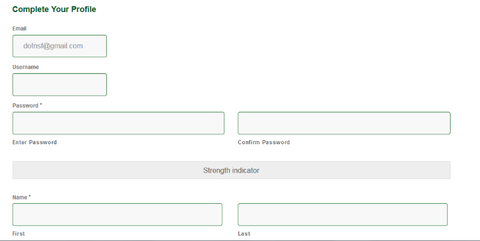
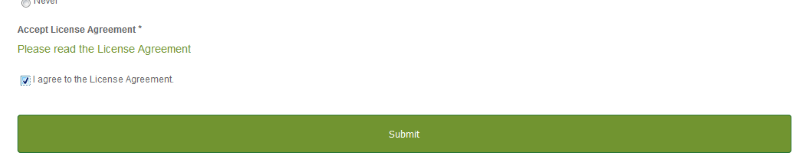
最後に同意チェックを入れて Submit !これでアカウント登録完了です:
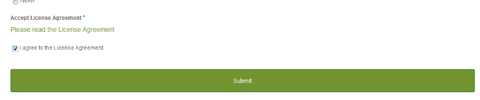
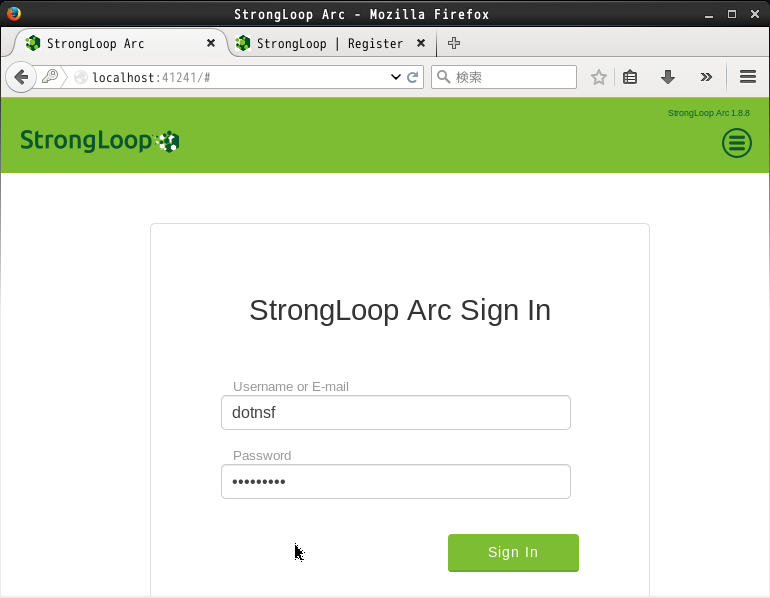
改めてこの画面から登録ユーザー名(またはメールアドレス)とパスワードを指定してログインします:
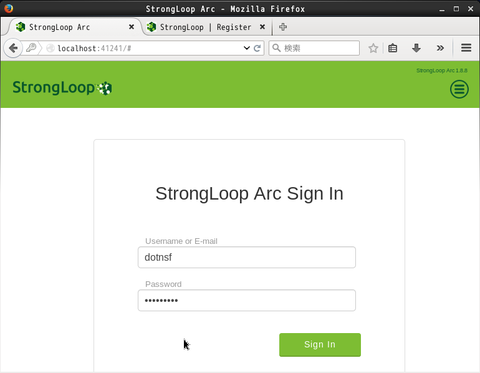
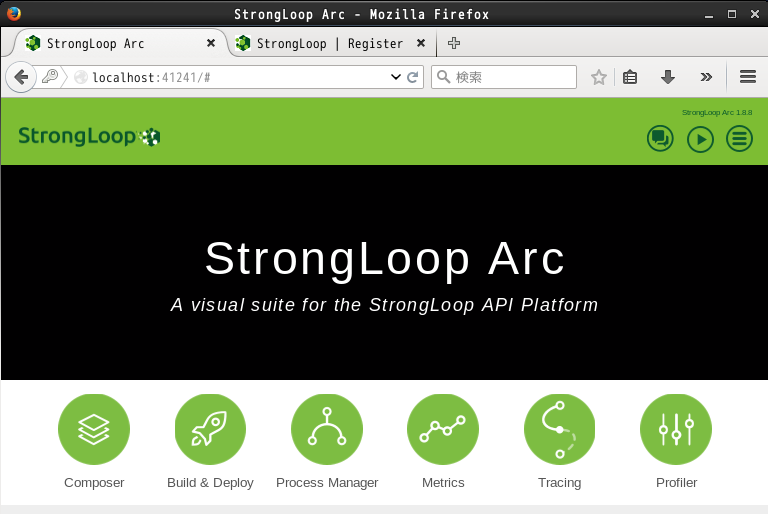
ログイン直後の画面がこちらです。コマンドラインの slc コマンドで行っていたような作業を GUI で行えるようになります:
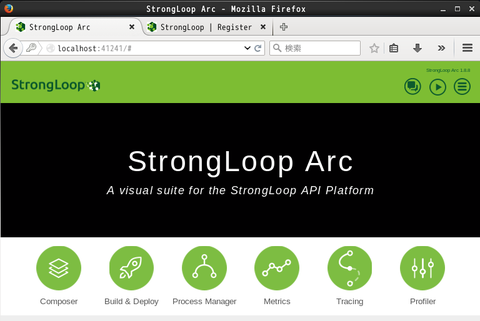
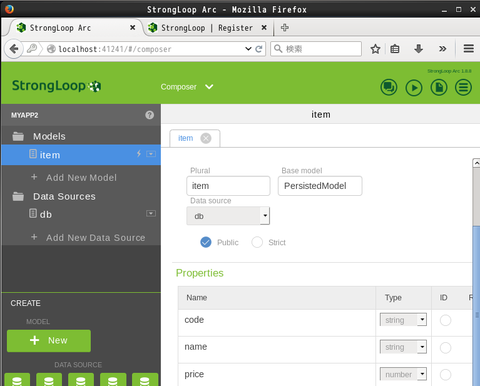
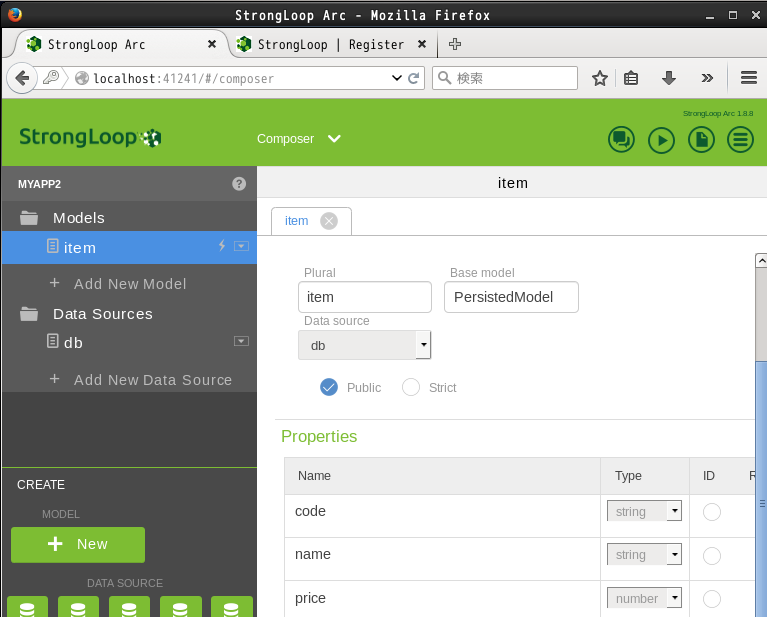
試しにデータソースを管理してみましょう。"Composer" をクリックすると、現在(LoopBack を使った時に登録した)データソースが確認でき、またここから新規にデータソースを定義することもできるようです:
プロセスマネージャーを登録してトレーシング・・・ などもやってみたかったのですが、何故か上手く行かなかったのでそちらについてはまた別途、かな。
https://strongloop.com/node-js/arc/
StrongLoop (や LoopBack )の slc コマンドを導入済みの環境であればすぐに使うことができます。試しに LoopBack で API を作った時の環境を使って、StrongLoop Arc を利用してみます。LoopBack を導入する手順についてはこちらを参照ください:
CentOS に StrongLoop をインストールする
上記手順を行い、"myapp2" という名前で LoopBack アプリケーションが作られていると仮定します。この環境を使って、StrongLoop Arc を利用するには、アプリケーションフォルダに移動して、"slc arc" コマンドを実行します:
# cd myapp2
# slc arc
するとこんな感じで StrongLoop Arc が起動します。以下の例では 41241 番ポートで起動していますが、このポート番号は動的に変わるようです:
ではこの環境にウェブブラウザでアクセスしてみましょう。なお、StrongLoop Arc はリモートアクセスを許可していないので、この StrongLoop 環境を導入したマシンそのものにログインしてからウェブブラウザで http://localhost:XXXXX/ にアクセスする必要があります:

StrongLoop Arc を使うにはアカウントが必要です。まだお持ちでない場合は画面右上のハンバーガーメニューから "register" を選んで登録を行います:
登録するユーザーのメールアドレスを指定して "Submit":

指定アドレスに StrongLoop からメールが届いたら、メール内のリンクをクリック:

で、ユーザー名やパスワードやら、残りの項目を登録します:

最後に同意チェックを入れて Submit !これでアカウント登録完了です:
改めてこの画面から登録ユーザー名(またはメールアドレス)とパスワードを指定してログインします:
ログイン直後の画面がこちらです。コマンドラインの slc コマンドで行っていたような作業を GUI で行えるようになります:
試しにデータソースを管理してみましょう。"Composer" をクリックすると、現在(LoopBack を使った時に登録した)データソースが確認でき、またここから新規にデータソースを定義することもできるようです:
プロセスマネージャーを登録してトレーシング・・・ などもやってみたかったのですが、何故か上手く行かなかったのでそちらについてはまた別途、かな。