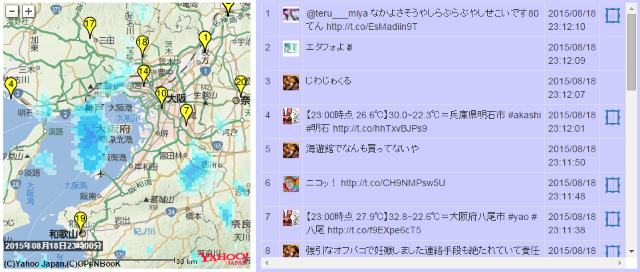
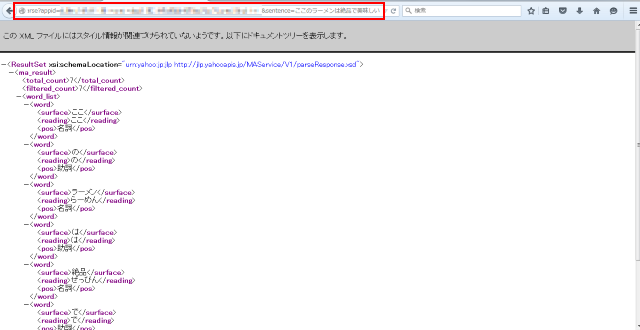
「人工知能が進化したら、人間の仕事がなくなる!?」とか「人工知能が人間の仕事を奪う!?」とか言われているのをたまに目にします:
http://nikkan-spa.jp/907607
個人的意見ですが、遅かれ早かれ&多かれ少なかれ、そういうことは出てくるんだろうなあ、、と思ってます。「絵画や小説など、芸術性/創造性の高い分野ではまだまだ」とも言われてますし、自分もその通りだとも思いますが、「まだまだ」ということは「いずれ・・・」という可能性を秘めているわけでもあります。
その一方で「人工知能が踏み込むことのできない分野もある」と思っています。人工知能がどれだけ発達しても、人間に追いつかないであろう分野があるとしたら、それは何だろう??と・・・
自分なりの答を1つ出すとしたら、それは「本能」だと思ってます。ニューラルネットワークやディープラーニングは「学習」させることで知能を得ます。この精度が高ければ高いほど、人間の脳に近づき、場合によっては人間を超えてしまうこともあると思っています。ただ、裏を返すとこの「学習」が人工知能の精度を高めているわけなので、何も学習させる前の人工知能はただの箱というか、「入力しても反応しないソフトウェア」でしかありません。
一方で人間には、何も教えていないのに既に体が知識を持っていたりします。特に生死に関わるようなもので、意志を伝えるために声や音を出すとか、身の危険を感じた時に自然に防御するとか、暑い時に汗をかいて体を冷やすとか、目の前にものが現れた時に(目を守ろうとして)目をつぶるとか、水中で呼吸を確保するために手足をバタバタさせるとか、、、DNA のレベルで学習済みというのか、動物や赤ちゃんが取る行動が近いといえるかもしれません。
もちろんこのような本能に近い行動をするようにコンピュータに学習させることはできると思いますが、「人はこれらのことを学習していなくてもわかっている、本能的に行動できる」という点が大きな違い、という意味です。
その意味で「人工知能が進化しても、自分の仕事を失わないようにするには?」を考えると、「仕事に本能に近い要素を取り入れること」と「自分の本能を磨き続ける」ことだと思ってます。例えば自分の場合であれば、お客様やイベントで製品の説明をする際に「どういう紹介の仕方をすれば驚いてくれるだろうか? 何を見せれば感動するだろうか?」といった、相手の本能を揺さぶるような観点を取り入れることを心がける、とか、頭や体を動かし続けて、自分の本能がサビつかないようにするとか、かなあ。
http://nikkan-spa.jp/907607
個人的意見ですが、遅かれ早かれ&多かれ少なかれ、そういうことは出てくるんだろうなあ、、と思ってます。「絵画や小説など、芸術性/創造性の高い分野ではまだまだ」とも言われてますし、自分もその通りだとも思いますが、「まだまだ」ということは「いずれ・・・」という可能性を秘めているわけでもあります。
その一方で「人工知能が踏み込むことのできない分野もある」と思っています。人工知能がどれだけ発達しても、人間に追いつかないであろう分野があるとしたら、それは何だろう??と・・・
自分なりの答を1つ出すとしたら、それは「本能」だと思ってます。ニューラルネットワークやディープラーニングは「学習」させることで知能を得ます。この精度が高ければ高いほど、人間の脳に近づき、場合によっては人間を超えてしまうこともあると思っています。ただ、裏を返すとこの「学習」が人工知能の精度を高めているわけなので、何も学習させる前の人工知能はただの箱というか、「入力しても反応しないソフトウェア」でしかありません。
一方で人間には、何も教えていないのに既に体が知識を持っていたりします。特に生死に関わるようなもので、意志を伝えるために声や音を出すとか、身の危険を感じた時に自然に防御するとか、暑い時に汗をかいて体を冷やすとか、目の前にものが現れた時に(目を守ろうとして)目をつぶるとか、水中で呼吸を確保するために手足をバタバタさせるとか、、、DNA のレベルで学習済みというのか、動物や赤ちゃんが取る行動が近いといえるかもしれません。
もちろんこのような本能に近い行動をするようにコンピュータに学習させることはできると思いますが、「人はこれらのことを学習していなくてもわかっている、本能的に行動できる」という点が大きな違い、という意味です。
その意味で「人工知能が進化しても、自分の仕事を失わないようにするには?」を考えると、「仕事に本能に近い要素を取り入れること」と「自分の本能を磨き続ける」ことだと思ってます。例えば自分の場合であれば、お客様やイベントで製品の説明をする際に「どういう紹介の仕方をすれば驚いてくれるだろうか? 何を見せれば感動するだろうか?」といった、相手の本能を揺さぶるような観点を取り入れることを心がける、とか、頭や体を動かし続けて、自分の本能がサビつかないようにするとか、かなあ。