IBM Bluemix から提供されている認識型人工知能 API の1つ "Speech to Text" が2015年7月1日のアップデートで日本語に対応しました!
http://www.ibm.com/smarterplanet/us/en/ibmwatson/developercloud/speech-to-text.html
音声ファイル(.wav など)をインプットとして与えると、その内容のテキストと、その変換の確度をテキストでアウトプットしてくれる、というサービスです。オンラインのデモサイトが用意されているので、まずはどのような内容なのかをデモで確認してみましょう:
https://speech-to-text-demo.mybluemix.net/
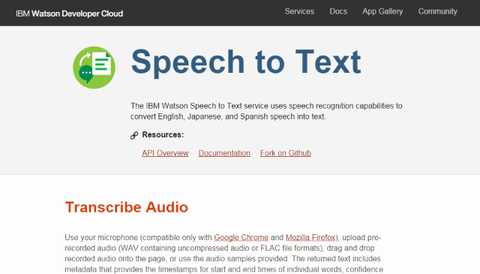
まず "Transcribe Audio" と書かれている所を参照し、今回のデモで行う作業を IBM Watson の学習にご協力いただけるかどうかを設定します。学習にご協力いただける場合は "Allow Watson to learn from this session" を、この作業を学習してほしくない場合は "Opt Out" を選択してください。更にその下で今回の作業で使う音声の言語情報を設定します。今回は日本語音声でテストしたいので "Japanese broadband model (16KHz)" を選択しておきます。加えて実際の音声が聞こえるように PC のスピーカーを有効にしておきます。これだけで事前準備は完了です:
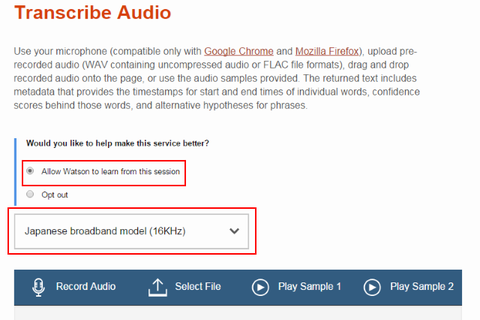
では実際にサンプル音声データを使って認識させてみます。"Play Sample 1" ボタンをクリックします:
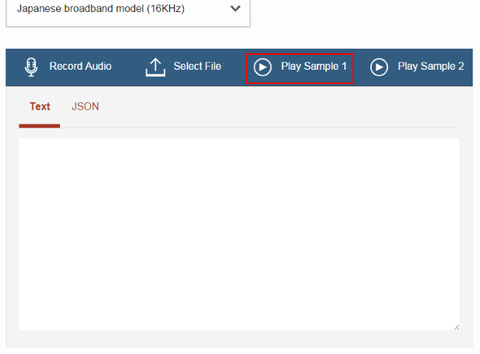
サンプルの日本語音声が流れ始めます。同時にその音声の認識結果が表示されはじめます。
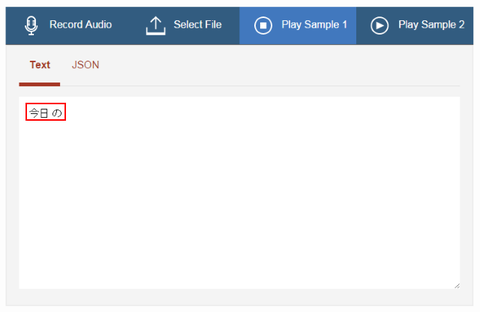
最後まで再生が終わると、最終認識結果が表示されます。実際に試していただくとわかるのですが、Sample 1 は正しい結果に認識できていることがわかります。しかもちゃんと漢字になっていますね。。:
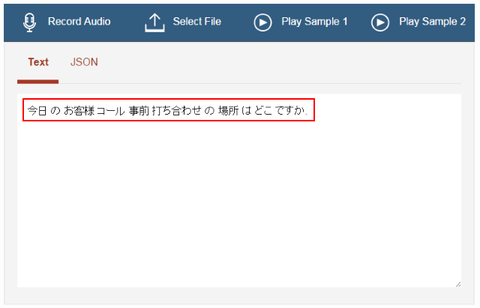
これが Watson Speech to Text API を使ったアプリの例です。このアプリで実現している内容と同様に、音声データをインプットとしてポストすると、認識結果がテキストで得られる、という API が用意されています。この API を自分のアプリケーションの中で利用することができる、というものです。
では実際にこの API をアプリケーションに組み込んで使ってみる、という具体例を紹介します。まずは Bluemix にログインし、実際のアプリケーションサーバーとなるランタイムを作成します。Speech to Text API は REST API なのでプログラミング言語に依存していませんが、今回は Java のサンプルを紹介するので Liberty for Java のランタイムを作成します:

アプリ名は適当に(この例では kkimura-java-s2t と)付けておきます:
ランタイムが作成できたら「概要」メニューから「サービスまたは API の追加」をクリックします:
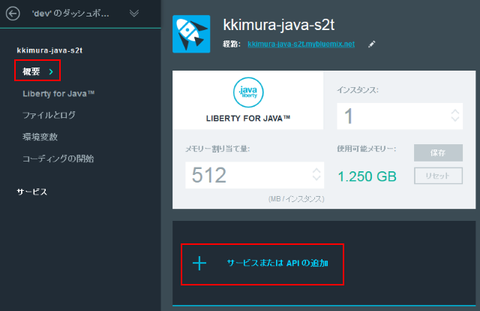
サービスの一覧が表示されます。今回の目的である Watson カテゴリ内の "Speech To Text" を選択します:

"Speech To Text" サービスの説明が表示されます。日本語に対応していることが確認できます。この画面で「作成」ボタンを押して、このサービスが先程作成したランタイムに紐付けた形で利用できるようにします:
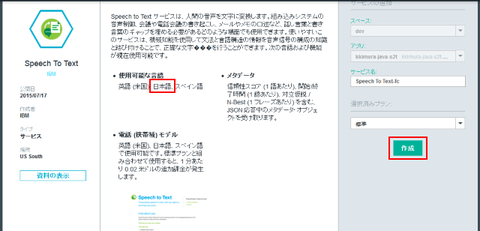
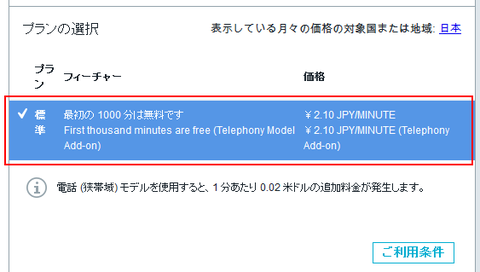
ちなみに、この画面の下部にはサービスの価格に関する情報も表示されているので念のため確認ください。この API は音声データの長さで課金されます。最初の 1000 分が無料、それ以降は1分につき 2.10 円です。なお無料トライアル期間中のユーザーは課金対象ではありません:
ランタイムに Speech to Text サービスが紐付けられると、ランタイムの環境変数からこのサービスを利用するための情報を参照できるようになります:
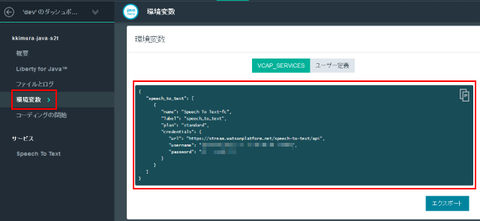
この環境情報はこのような内容になっているはずです。"url" に API のエンドポイント(のベースとなる)値、そして "username" と "password" にはこの API を利用する際に必要になる認証情報が記載されています。これらの値を後で使います:
そして、実際に API にポストする日本語音声ファイルを用意します。今回はこちらのサイトから「あいうえお1(wav)」と書かれた .wav ファイル(aiueo1.wav)をダウンロードして使わせていただくことにします。もちろん他の音声ファイルでも構いません。現時点での対応フォーマットは flac/l16/wav です:
日本語音声サンプル
で、こんな感じのアプリケーションを作ってみました。まずはシンプルに音声ファイルを指定してアップロードする HTML ページのファイルです。アップロードするファイルは "audio_file" という名前で、./speech2text にポストします:
そして、このページからアップロードされた音声ファイルを使って Speech To Text API を実行して、その結果を返すサーブレット(./speech2text)を以下の内容で作成します。なおこのサーブレットは Jakarta Commons HTTPClient 3.1 と JSON Simple 1.1.1 を使っています。必要であればこれらのモジュールも入手してください:
肝になっているのは赤字で記載した部分です。Speech to Text には何種類かの API がありますが、今回はシンプルに実行する /v1/recognize を使った例を紹介しています。この API はまず model パラメータで言語情報を指定します。今回は日本語音声ファイルを試したいので、model=ja-JP_BroadbandModel と決め打ちで指定しています。これ以外にも認識の途中経過を結果テキストに含めるような指定をすることもできますが、今回は認識した最終結果だけをその確度と一緒に返す仕様(デフォルト)で実行しています。
そして環境変数で確認した username と password を使った Basic 認証、および認識させる音声ファイルの Content-Type を HTTP ヘッダに追加し、音声ファイルのバイナリを本体としてする、という内容になっています。上記例は Java でその内容を実装していますが、同様の処理を記述すれば他の言語でも同じ処理を実行できるはずです。
この処理が成功すると、HTTP のレスポンス(上記コードの※の out の内容)として以下の様な JSON テキストが返されるはずです:
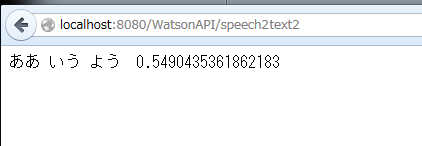
上記の中身の "transcript" が認識結果のテキスト(「あいうえお」のはずが「ああ いう よう」と聞こえちゃったんですね。。)、その確度が "confidence" に付与されています。 なので、この JSON フォーマットから目的の値だけを取り出して、上記例では "transcript" と "confidence" の値をタブ("\t")でつないで返す、という内容のサーブレットにしました。
したがって、このプログラムを実際に動かして、用意した aiueo1.wav をアップロードすると、このような結果がブラウザ画面に表示されることになります:
Watson Speech to Text API の特徴の1つとして、「一般的な会話がなされている前提で、会話として確率の高そうな結果が優先される」ように感じています。上記例だと、一般的な会話の中には「あいうえお」という発音だけがなされる可能性は低いのも事実だと思っています。一方で「ああ、言うよ~」はより会話っぽいので、こういう結果の方がどちらかというと(会話として)可能性が高い、と判断するようです。良くも悪くも会話優先で変換してくれるような印象を持っています。
と、これが Watson の Speech to Text API の具体的な利用例です。パラメータで挙動をある程度コントロールすることもできますし、結果により詳しい情報を含めることもできます。音声というメディアをアプリケーションに組み組むのに便利な API だと思うので、様々なアプリアイデアの中で使ってみてください。
なお、Speech to Text API のリファレンスはこちらを参照ください:
http://www.ibm.com/smarterplanet/us/en/ibmwatson/developercloud/apis/#!/speech-to-text/
http://www.ibm.com/smarterplanet/us/en/ibmwatson/developercloud/speech-to-text.html
音声ファイル(.wav など)をインプットとして与えると、その内容のテキストと、その変換の確度をテキストでアウトプットしてくれる、というサービスです。オンラインのデモサイトが用意されているので、まずはどのような内容なのかをデモで確認してみましょう:
https://speech-to-text-demo.mybluemix.net/

まず "Transcribe Audio" と書かれている所を参照し、今回のデモで行う作業を IBM Watson の学習にご協力いただけるかどうかを設定します。学習にご協力いただける場合は "Allow Watson to learn from this session" を、この作業を学習してほしくない場合は "Opt Out" を選択してください。更にその下で今回の作業で使う音声の言語情報を設定します。今回は日本語音声でテストしたいので "Japanese broadband model (16KHz)" を選択しておきます。加えて実際の音声が聞こえるように PC のスピーカーを有効にしておきます。これだけで事前準備は完了です:

では実際にサンプル音声データを使って認識させてみます。"Play Sample 1" ボタンをクリックします:

サンプルの日本語音声が流れ始めます。同時にその音声の認識結果が表示されはじめます。

最後まで再生が終わると、最終認識結果が表示されます。実際に試していただくとわかるのですが、Sample 1 は正しい結果に認識できていることがわかります。しかもちゃんと漢字になっていますね。。:

これが Watson Speech to Text API を使ったアプリの例です。このアプリで実現している内容と同様に、音声データをインプットとしてポストすると、認識結果がテキストで得られる、という API が用意されています。この API を自分のアプリケーションの中で利用することができる、というものです。
では実際にこの API をアプリケーションに組み込んで使ってみる、という具体例を紹介します。まずは Bluemix にログインし、実際のアプリケーションサーバーとなるランタイムを作成します。Speech to Text API は REST API なのでプログラミング言語に依存していませんが、今回は Java のサンプルを紹介するので Liberty for Java のランタイムを作成します:

アプリ名は適当に(この例では kkimura-java-s2t と)付けておきます:
ランタイムが作成できたら「概要」メニューから「サービスまたは API の追加」をクリックします:

サービスの一覧が表示されます。今回の目的である Watson カテゴリ内の "Speech To Text" を選択します:

"Speech To Text" サービスの説明が表示されます。日本語に対応していることが確認できます。この画面で「作成」ボタンを押して、このサービスが先程作成したランタイムに紐付けた形で利用できるようにします:

ちなみに、この画面の下部にはサービスの価格に関する情報も表示されているので念のため確認ください。この API は音声データの長さで課金されます。最初の 1000 分が無料、それ以降は1分につき 2.10 円です。なお無料トライアル期間中のユーザーは課金対象ではありません:

ランタイムに Speech to Text サービスが紐付けられると、ランタイムの環境変数からこのサービスを利用するための情報を参照できるようになります:

この環境情報はこのような内容になっているはずです。"url" に API のエンドポイント(のベースとなる)値、そして "username" と "password" にはこの API を利用する際に必要になる認証情報が記載されています。これらの値を後で使います:
{
"speech_to_text": [
{
"name": "Speech To Text-fc",
"label": "speech_to_text",
"plan": "standard",
"credentials": {
"url": "https://stream.watsonplatform.net/speech-to-text/api",
"username": "(username)",
"password": "(password)"
}
}
]
}
そして、実際に API にポストする日本語音声ファイルを用意します。今回はこちらのサイトから「あいうえお1(wav)」と書かれた .wav ファイル(aiueo1.wav)をダウンロードして使わせていただくことにします。もちろん他の音声ファイルでも構いません。現時点での対応フォーマットは flac/l16/wav です:
日本語音声サンプル
で、こんな感じのアプリケーションを作ってみました。まずはシンプルに音声ファイルを指定してアップロードする HTML ページのファイルです。アップロードするファイルは "audio_file" という名前で、./speech2text にポストします:
<html> <head> <title>Speech to Text</title> </head> <body> <form name="frm" method="post" enctype="multipart/form-data" action="./speech2text"> <input type="file" name="audio_file"/><input type="submit" value="Submit"/> </form> </body> </html>
そして、このページからアップロードされた音声ファイルを使って Speech To Text API を実行して、その結果を返すサーブレット(./speech2text)を以下の内容で作成します。なおこのサーブレットは Jakarta Commons HTTPClient 3.1 と JSON Simple 1.1.1 を使っています。必要であればこれらのモジュールも入手してください:
import java.io.ByteArrayOutputStream;
import java.io.IOException;
import java.io.InputStream;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import org.apache.commons.codec.binary.Base64;
import org.apache.commons.fileupload.FileItemIterator;
import org.apache.commons.fileupload.FileItemStream;
import org.apache.commons.fileupload.servlet.ServletFileUpload;
import org.apache.commons.httpclient.HttpClient;
import org.apache.commons.httpclient.methods.ByteArrayRequestEntity;
import org.apache.commons.httpclient.methods.PostMethod;
import org.json.simple.JSONArray;
import org.json.simple.JSONObject;
import org.json.simple.parser.JSONParser;
public class SpeechToTextServlet extends HttpServlet {
@Override
protected void doPost( HttpServletRequest req, HttpServletResponse res ) throws ServletException, IOException{
String contenttype = "application/json; charset=UTF-8";
String audio_type = "audio/wav";
byte[] audio_file = null;
String out = "";
// Speech to Text を使うための username と password(環境変数にかかれていたもの)
String username = "(username)", password = "(password)";
req.setCharacterEncoding( "UTF-8" );
ServletFileUpload upload = new ServletFileUpload();
upload.setHeaderEncoding( "UTF-8" );
JSONParser parser = new JSONParser();
try{
FileItemIterator iterator = upload.getItemIterator( req );
while( iterator.hasNext() ){
FileItemStream item = iterator.next();
InputStream stream = item.openStream();
if( !item.isFormField() ){
String fieldname = item.getFieldName();
// audio_file フィールドに指定された音声ファイルのバイナリを取得する
if( fieldname.equals( "audio_file" ) ){
audio_type = item.getContentType(); // 音声ファイルの Content-Type
int len, size = 0;
byte[] buffer = new byte[10*1024*1024]; //. 10MB MAX
ByteArrayOutputStream baos = new ByteArrayOutputStream();
while( ( len = stream.read( buffer, 0, buffer.length ) ) != -1 ){
baos.write( buffer, 0, len );
size += len;
}
audio_file = baos.toByteArray(); // 音声ファイルのバイト配列
}
}
}
if( audio_file != null ){
HttpClient client = new HttpClient();
byte[] b64data = Base64.encodeBase64( ( username + ":" + password ).getBytes() );
// /v1/recognize に音声ファイルのバイナリをポストする(パラメータで日本語音声であることを指定)
PostMethod post = new PostMethod( "https://stream.watsonplatform.net/speech-to-text/api/v1/recognize?model=ja-JP_BroadbandModel" );
post.setRequestHeader( "Authorization", "Basic " + new String( b64data ) );
post.setRequestHeader( "Content-Type", audio_type );
ByteArrayRequestEntity entity = new ByteArrayRequestEntity( audio_file );
post.setRequestEntity( entity );
int sc = client.executeMethod( post );
if( sc == 200 ){
// ポスト結果(JSON)を UTF-8 テキストで取り出す
byte[] b = post.getResponseBody();
out = new String( b, "UTF-8" ); // ※
// テキスト内の日本語認識結果と、その確度(自信)を取り出す
JSONObject obj = ( JSONObject )parser.parse( out );
JSONArray results = ( JSONArray )obj.get( "results" );
if( results.size() > 0 ){
JSONObject result = ( JSONObject )results.get( 0 );
JSONArray alternatives = ( JSONArray )result.get( "alternatives" );
for( int i = 0; i < alternatives.size(); i ++ ){
JSONObject alternative = ( JSONObject )alternatives.get( i );
Double confidence = ( Double )alternative.get( "confidence" );
String transcript = ( String )alternative.get( "transcript" );
out = transcript + "\t" + confidence; // 結果をタブでつないで出力する
//System.out.println( out );
}
}
}
}
}catch( Exception e ){
e.printStackTrace();
}
res.setContentType( contenttype );
res.setCharacterEncoding( "UTF-8" );
res.getWriter().println( out );
}
}
肝になっているのは赤字で記載した部分です。Speech to Text には何種類かの API がありますが、今回はシンプルに実行する /v1/recognize を使った例を紹介しています。この API はまず model パラメータで言語情報を指定します。今回は日本語音声ファイルを試したいので、model=ja-JP_BroadbandModel と決め打ちで指定しています。これ以外にも認識の途中経過を結果テキストに含めるような指定をすることもできますが、今回は認識した最終結果だけをその確度と一緒に返す仕様(デフォルト)で実行しています。
そして環境変数で確認した username と password を使った Basic 認証、および認識させる音声ファイルの Content-Type を HTTP ヘッダに追加し、音声ファイルのバイナリを本体としてする、という内容になっています。上記例は Java でその内容を実装していますが、同様の処理を記述すれば他の言語でも同じ処理を実行できるはずです。
この処理が成功すると、HTTP のレスポンス(上記コードの※の out の内容)として以下の様な JSON テキストが返されるはずです:
{
"results": [
{
"alternatives": [
{
"confidence": 0.5490435361862183,
"transcript": "ああ いう よう "
}
],
"final": true
}
],
"result_index": 0
}
上記の中身の "transcript" が認識結果のテキスト(「あいうえお」のはずが「ああ いう よう」と聞こえちゃったんですね。。)、その確度が "confidence" に付与されています。 なので、この JSON フォーマットから目的の値だけを取り出して、上記例では "transcript" と "confidence" の値をタブ("\t")でつないで返す、という内容のサーブレットにしました。
したがって、このプログラムを実際に動かして、用意した aiueo1.wav をアップロードすると、このような結果がブラウザ画面に表示されることになります:
Watson Speech to Text API の特徴の1つとして、「一般的な会話がなされている前提で、会話として確率の高そうな結果が優先される」ように感じています。上記例だと、一般的な会話の中には「あいうえお」という発音だけがなされる可能性は低いのも事実だと思っています。一方で「ああ、言うよ~」はより会話っぽいので、こういう結果の方がどちらかというと(会話として)可能性が高い、と判断するようです。良くも悪くも会話優先で変換してくれるような印象を持っています。
と、これが Watson の Speech to Text API の具体的な利用例です。パラメータで挙動をある程度コントロールすることもできますし、結果により詳しい情報を含めることもできます。音声というメディアをアプリケーションに組み組むのに便利な API だと思うので、様々なアプリアイデアの中で使ってみてください。
なお、Speech to Text API のリファレンスはこちらを参照ください:
http://www.ibm.com/smarterplanet/us/en/ibmwatson/developercloud/apis/#!/speech-to-text/