前回の記事の後編です。Watson の画像認識機能そのものを紹介した前編はこちらを参照ください:
Watson の画像認識 API を使う(1/2)
前回は Watson Visual Recognition(画像認識)の機能を理解するために、実際にデモサイトを使って体験してみる、という内容を紹介しました。今回は IBM Bluemix から提供されている API を使って、実際に画像認識を行うサンプルコードを紹介します。前提条件として IBM Bluemix のアカウントが必要です。お持ちでない場合はこちらのサイトを参照して、30日間無料トライアルアカウントを取得してください:
http://ibm.biz/BMtrial
アカウントが取得できたら Bluemix にログインします。Visual Recognition サービスを使うためには、そのサービスに紐付けるランタイム(アプリケーション・サーバー)を指定する必要があるため、ランタイムを1つ作ります(既に Bluemix をお使いの方で、ランタイムも定義済みであれば、そのランタイムをそのままお使いいただいても構いません)。今回は Java のサンプルを紹介するので Java アプリケーションサーバーである Liberty Java を選択して作成します:
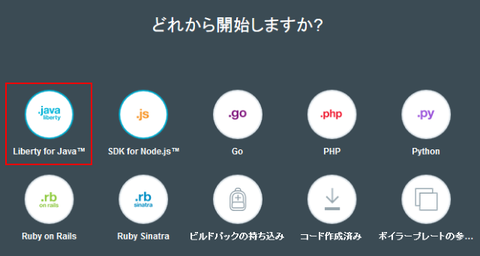
なお、Visual Recognition API 自体は REST なので、ランタイムは Java でなくても構いませんが、本エントリでは Java のサンプルを紹介します。Visual Recognition の API ドキュメントはこちらを参照ください(ただし 2015/Mar/11 時点でパラメータ名が間違ってます、正しい使い方は以下のコードを参照ください):
visual-recognition : REST methods for IBM Visual Recognition
ランタイムが作成されたら、このランタイムに Visual Recognition サービスを紐付ける形で追加します:

Visual Recognition サービスを使うための認証情報(ID とパスワード)を確認します。ランタイムを選択して環境変数 VCAP_SERVICES 内の credentials.username と credential.password の値を参照します:
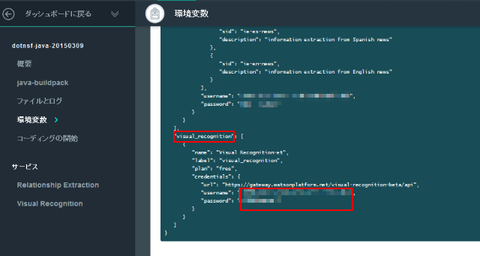
ここまでの作業で Visual Recognition サービスを使うために必要な準備と情報は整いました。後はコードを書くだけです。
今回紹介するサンプルでは (1) 画像をアップロードして、(2) その画像を Visual Recognition API で調べて、結果の JSON をそのまま出力する、というシンプルな例とします。
まずは (1) の部分を HTML で用意します。一切装飾してませんが、こんな感じでしょうか:
そして (2) の部分を Java サーブレットで作成します。(1) で /visualrecognition というアクションに multipart/form-data で画像ファイルを POST するように指定しているので、その内容を受け取って処理するような内容にしています。またファイルアップロードと HTTP アクセスを実装するためのライブラリ(Jakarta Commons の fileupload, codec, logging, httpclient3)を追加して使っています:
このコードは(ファイルアップロードでは一般的な)マルチパートで送られてくる画像データを受け取って、そのバイナリ情報をバイト配列の img_file 変数に格納します(この例では 4MB を上限としています)。
img_file の中身が正しく取得できていたら、Visual Recognition API を実行します。Basic 認証が必要なので、Visual Recognition サービスを追加したランタイムの環境変数 VCAP_SERVICES から credentials の username と password の値を取り出して、この例ではそれぞれ変数に格納しています(実際には動的に取得することをおすすめします)。Basic 認証のヘッダを作成すると同時に、この画像バイナリ情報をマルチパートで API のエンドポイント(https://gateway.watsonplatform.net/visual-recognition-beta/api/v1/tag/recognize)に POST で送ります。その際の指定方法は FilePart で変数名は imgFile、ファイル名は任意ですが拡張子が .jpg になるように(上例では "imgFile.jpg" で固定値)する必要があるそうです。
なお、このマルチパート部分には、画像のカテゴリがあらかじめわかっている時のためのカテゴリ指定を追加することも可能です。その場合は別の API エンドポイント: https://gateway.watsonplatform.net/visual-recognition-beta/api/v1/tag/labels を GET コールして得られる結果を絞る形で JSON を作り、StringPart で作成した文字列を指定します(上記例では青でコメントにしている部分です)。このサンプルでは使っていないので、特にカテゴリを指定せずに解析しています。
最後に API を実行した結果の文字列を取得して、"Content-Type: application/json" で出力する、というサンプルです。エラーハンドリングなど、甘い部分もまだありますが、おおまかな流れがご理解いただけると思います。
このプロジェクトアプリケーションを実行して、HTML ページにアクセスすると、画像ファイルを指定するこんなシンプルな画面になります:

ローカルシステム内の画像ファイルを1つ指定してサーブレットを呼び出すと、上記のコードが実行され、Watson Visual Recognition API が実行され、その結果の JSON テキストが画面に出力されます:

ちなみに指定した画像はこれ(木更津市のマンホール)でした。"Dog" かあ、惜しいなあ。でもタヌキは「イヌ科」だからほぼ正解と言えますよね! <ポジティブシンキング

Watson の画像認識 API を使う(1/2)
前回は Watson Visual Recognition(画像認識)の機能を理解するために、実際にデモサイトを使って体験してみる、という内容を紹介しました。今回は IBM Bluemix から提供されている API を使って、実際に画像認識を行うサンプルコードを紹介します。前提条件として IBM Bluemix のアカウントが必要です。お持ちでない場合はこちらのサイトを参照して、30日間無料トライアルアカウントを取得してください:
http://ibm.biz/BMtrial
アカウントが取得できたら Bluemix にログインします。Visual Recognition サービスを使うためには、そのサービスに紐付けるランタイム(アプリケーション・サーバー)を指定する必要があるため、ランタイムを1つ作ります(既に Bluemix をお使いの方で、ランタイムも定義済みであれば、そのランタイムをそのままお使いいただいても構いません)。今回は Java のサンプルを紹介するので Java アプリケーションサーバーである Liberty Java を選択して作成します:

なお、Visual Recognition API 自体は REST なので、ランタイムは Java でなくても構いませんが、本エントリでは Java のサンプルを紹介します。Visual Recognition の API ドキュメントはこちらを参照ください(ただし 2015/Mar/11 時点でパラメータ名が間違ってます、正しい使い方は以下のコードを参照ください):
visual-recognition : REST methods for IBM Visual Recognition
ランタイムが作成されたら、このランタイムに Visual Recognition サービスを紐付ける形で追加します:
Visual Recognition サービスを使うための認証情報(ID とパスワード)を確認します。ランタイムを選択して環境変数 VCAP_SERVICES 内の credentials.username と credential.password の値を参照します:
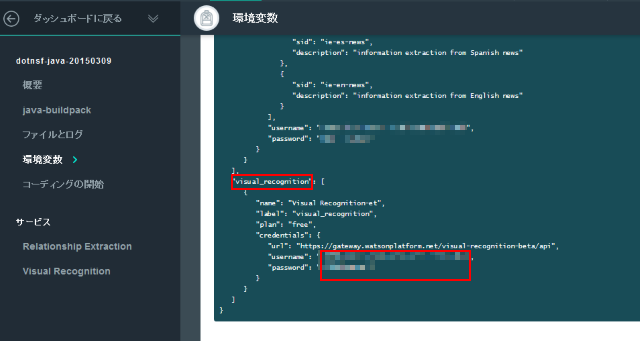
ここまでの作業で Visual Recognition サービスを使うために必要な準備と情報は整いました。後はコードを書くだけです。
今回紹介するサンプルでは (1) 画像をアップロードして、(2) その画像を Visual Recognition API で調べて、結果の JSON をそのまま出力する、というシンプルな例とします。
まずは (1) の部分を HTML で用意します。一切装飾してませんが、こんな感じでしょうか:
<html> <head> <title>Visual Recognition</title> </head> <body> <form name="frm" method="post" enctype="multipart/form-data" action="./visualrecognition"> <input type="file" name="img_file"/><input type="submit" value="Upload" /> </form> </body> </html>
そして (2) の部分を Java サーブレットで作成します。(1) で /visualrecognition というアクションに multipart/form-data で画像ファイルを POST するように指定しているので、その内容を受け取って処理するような内容にしています。またファイルアップロードと HTTP アクセスを実装するためのライブラリ(Jakarta Commons の fileupload, codec, logging, httpclient3)を追加して使っています:
:
:
import java.io.*;
import javax.servlet.*;
import javax.servlet.http.*;
import org.apache.commons.codec.binary.Base64;
import org.apache.commons.fileupload.*;
import org.apache.commons.fileupload.servlet.*;
import org.apache.commons.httpclient.*;
import org.apache.commons.httpclient.methods.*;
import org.apache.commons.httpclient.methods.multipart.*;
public class VisualRecognitionServlet extends HttpServlet {
private String username = "(Visual Recognition API の username の値)";
private String password = "(Visual Recognition API の password の値)";
@Override
protected void doPost( HttpServletRequest req, HttpServletResponse res ) throws ServletException, IOException{
String contenttype = "application/json; charset=UTF-8";
String body = "";
byte[] img_file = null;
String out = "";
ServletFileUpload upload = new ServletFileUpload();
try{
FileItemIterator iterator = upload.getItemIterator( req );
while( iterator.hasNext() ){
FileItemStream item = iterator.next();
InputStream stream = item.openStream();
if( item.isFormField() ){
}else{
String fieldname = item.getFieldName();
if( fieldname.equals( "img_file" ) ){
byte[] buffer = new byte[4*1024*1024]; //. 4MB上限
ByteArrayOutputStream baos = new ByteArrayOutputStream();
while( ( len = stream.read( buffer, 0, buffer.length ) ) != -1 ){
baos.write( buffer, 0, len );
size += len;
}
img_file = baos.toByteArray();
}
}
}
if( img_file != null && img_file.length > 0 ){
HttpClient client = new HttpClient();
byte[] b64data = Base64.encodeBase64( ( username + ":" + password ).getBytes() );
PostMethod post = new PostMethod( "https://gateway.watsonplatform.net/visual-recognition-beta/api/v1/tag/recognize" );
Part[] parts = new Part[]{
//new StringPart( "labels_to_check", "{\"label_groups\":[\"Vehicle\"],\"labels\":[\"Mixed_Type\"]}" ),
new FilePart( "imgFile", new ByteArrayPartSource( "imgFile.jpg", img_file ) )
};
post.setRequestHeader( "Authorization", "Basic " + new String( b64data ) );
post.setRequestEntity( new MultipartRequestEntity( parts, post.getParams() ) );
//post.setRequestHeader( "Content-Type", "multipart/form-data" ); //. 自分で設定してはダメ
out = post.getResponseBodyAsString();
//System.out.println( out );
}
}catch( Exception e ){
e.printStackTrace();
}
res.setContentType( contenttype );
res.setCharacterEncoding( "UTF-8" );
res.getWriter().println( out );
}
}
このコードは(ファイルアップロードでは一般的な)マルチパートで送られてくる画像データを受け取って、そのバイナリ情報をバイト配列の img_file 変数に格納します(この例では 4MB を上限としています)。
img_file の中身が正しく取得できていたら、Visual Recognition API を実行します。Basic 認証が必要なので、Visual Recognition サービスを追加したランタイムの環境変数 VCAP_SERVICES から credentials の username と password の値を取り出して、この例ではそれぞれ変数に格納しています(実際には動的に取得することをおすすめします)。Basic 認証のヘッダを作成すると同時に、この画像バイナリ情報をマルチパートで API のエンドポイント(https://gateway.watsonplatform.net/visual-recognition-beta/api/v1/tag/recognize)に POST で送ります。その際の指定方法は FilePart で変数名は imgFile、ファイル名は任意ですが拡張子が .jpg になるように(上例では "imgFile.jpg" で固定値)する必要があるそうです。
なお、このマルチパート部分には、画像のカテゴリがあらかじめわかっている時のためのカテゴリ指定を追加することも可能です。その場合は別の API エンドポイント: https://gateway.watsonplatform.net/visual-recognition-beta/api/v1/tag/labels を GET コールして得られる結果を絞る形で JSON を作り、StringPart で作成した文字列を指定します(上記例では青でコメントにしている部分です)。このサンプルでは使っていないので、特にカテゴリを指定せずに解析しています。
最後に API を実行した結果の文字列を取得して、"Content-Type: application/json" で出力する、というサンプルです。エラーハンドリングなど、甘い部分もまだありますが、おおまかな流れがご理解いただけると思います。
このプロジェクトアプリケーションを実行して、HTML ページにアクセスすると、画像ファイルを指定するこんなシンプルな画面になります:

ローカルシステム内の画像ファイルを1つ指定してサーブレットを呼び出すと、上記のコードが実行され、Watson Visual Recognition API が実行され、その結果の JSON テキストが画面に出力されます:

ちなみに指定した画像はこれ(木更津市のマンホール)でした。"Dog" かあ、惜しいなあ。でもタヌキは「イヌ科」だからほぼ正解と言えますよね! <ポジティブシンキング