IBM Bluemix から提供される各種 API の使い方をリファレンスで調べていると、確かにドキュメント化されてはいるのですが、具体的にどう使えばいいのか? と悩むことはないでしょうか?
例えば、このリンク先には Watson の Speech To Text サービス内の /v1/sessions/{$sessionid}/recognize 関数の使い方についての説明が書かれています:
http://www.ibm.com/smarterplanet/us/en/ibmwatson/developercloud/apis/#!/speech-to-text/recognizeSession
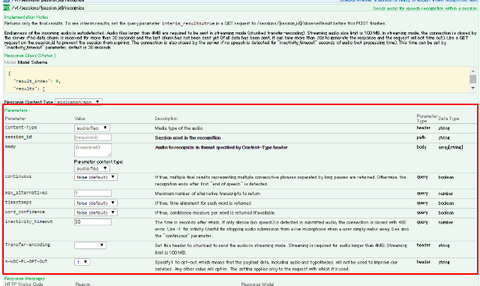
このページを見て、具体的にどのようなエンドポイントにどのようなヘッダとパラメータでアクセスすればよいか、わかりますか? 分かる人はすぐに分かると思いますが、ちょっとクセのある書き方なので、具体的な指定方法がイメージしにくいかもしれません。その確認の意味も込めて説明します。
まず、上記ページの "Parameters" にはこのように書かれています:

この表の "Parameter" と "Parameter Type" と書かれた2列に注目して、この2列だけを取り出してみるとこのようになります:
"Content-Type" パラメータのタイプは "header" ということになっています。これが何を意味するかというと、「Content-Type を HTTP ヘッダで指定する」ということを意味しています。Transfer-encoding や X-WDC-PL-OPT-OUT も HTTP ヘッダとして指定する必要がある、ということになります。
次に "session_id" パラメータのタイプは "path" です。これは「API エンドポイントの URI を指定する際のパスの一部として session_id を指定する」ということです。実際、この API のエンドポイントは /v1/sessions/{$sessionid}/recognize であり、この {$sessionid} 部分に session_id を指定することになるので、確かにパスの一部に session_id を指定していると言えますね。
そして body パラメータタイプは body 、つまり body に相当する情報をポストの本文として指定することが想定されている、ということになります。
最後に continuous や max_alternatives パラメータのタイプは query です。これはエンドポイントのクエリーとして、例えば /v1/sessions/{$sessionid}/recognize?continuous=true&max_alternatives=5 のように指定することを意味します。
以上をまとめると、リファレンスのパラメータータイプはこのように理解すればよい、ということになります:
(1) path はエンドポイント URI の一部に埋め込む形で指定
(2) query はエンドポイント URI のパラメータとして指定
(3) header は HTTP ヘッダとして指定
(4) body はポストの本文として指定
この記述ルールがわかっていると Bluemix の API リファレンスも読みやすくなりますね。
例えば、このリンク先には Watson の Speech To Text サービス内の /v1/sessions/{$sessionid}/recognize 関数の使い方についての説明が書かれています:
http://www.ibm.com/smarterplanet/us/en/ibmwatson/developercloud/apis/#!/speech-to-text/recognizeSession

このページを見て、具体的にどのようなエンドポイントにどのようなヘッダとパラメータでアクセスすればよいか、わかりますか? 分かる人はすぐに分かると思いますが、ちょっとクセのある書き方なので、具体的な指定方法がイメージしにくいかもしれません。その確認の意味も込めて説明します。
まず、上記ページの "Parameters" にはこのように書かれています:

この表の "Parameter" と "Parameter Type" と書かれた2列に注目して、この2列だけを取り出してみるとこのようになります:
| Parameter | Parameter Type |
|---|---|
| Content-Type | header |
| session_id | path |
| body | body |
| continuous | query |
| max_alternatives | query |
| time_stamps | query |
| word_confidence | query |
| inactivity_timeout | query |
| Transfer-encoding | header |
| X-WDC-PL-OPT-OUT | header |
"Content-Type" パラメータのタイプは "header" ということになっています。これが何を意味するかというと、「Content-Type を HTTP ヘッダで指定する」ということを意味しています。Transfer-encoding や X-WDC-PL-OPT-OUT も HTTP ヘッダとして指定する必要がある、ということになります。
次に "session_id" パラメータのタイプは "path" です。これは「API エンドポイントの URI を指定する際のパスの一部として session_id を指定する」ということです。実際、この API のエンドポイントは /v1/sessions/{$sessionid}/recognize であり、この {$sessionid} 部分に session_id を指定することになるので、確かにパスの一部に session_id を指定していると言えますね。
そして body パラメータタイプは body 、つまり body に相当する情報をポストの本文として指定することが想定されている、ということになります。
最後に continuous や max_alternatives パラメータのタイプは query です。これはエンドポイントのクエリーとして、例えば /v1/sessions/{$sessionid}/recognize?continuous=true&max_alternatives=5 のように指定することを意味します。
以上をまとめると、リファレンスのパラメータータイプはこのように理解すればよい、ということになります:
(1) path はエンドポイント URI の一部に埋め込む形で指定
(2) query はエンドポイント URI のパラメータとして指定
(3) header は HTTP ヘッダとして指定
(4) body はポストの本文として指定
この記述ルールがわかっていると Bluemix の API リファレンスも読みやすくなりますね。


コメント
コメント一覧 (2)
こちらのブログを参考にさせていただいて IBM Watson API を Ruby から使うためのライブラリ watson-api-client を作ってみました。
gems: https://rubygems.org/gems/watson-api-client
code: https://github.com/suchowan/watson-api-client
メタプログラミングなので本体コードは100行程度です。
パラメータータイプは気にしなくてよいのですが、操作のニックネームがメソッド名になるのが使い勝手の上で気になるところです。
Watson 日本語版がリリースされた由。
大いに利用させていただきたいと思います。
さて、前回ご紹介した https://github.com/suchowan/watson-api-client 。
参照していた API のリスト
http://www.ibm.com/smarterplanet/us/en/ibmwatson/developercloud/apis/listings/api-docs.json が空になってしまいました。
とりあえず人間用の Web page をパースして API定義ファイルを取得するようにしましたが、本来は、以前と同じく API定義ファイルのリストが1ファイルで読めるようになっているべきではないかと思います。
担当者に要望をお伝えいただければと希望いたします。