2016 年の年初に「マンホライザー」というサービスを作って動かしていました:
http://dotnsf.blog.jp/archives/1048853473.html
マンホライザーはわかりやすく言うと「マンホール顔ハメ画像作成サービス」です(わかりやすいか??)。先日のマンホールサミット 2017 埼玉に参加した際にも、こんなアナログな顔ハメ写真サービスを提供させていただいたのですが、意外と人気があったのでした。それをウェブ上からもできるようにしよう、というわけで生まれたサービスでした。IBM Watson の画像認識機能を使って実装しており、「テクノロジーの無駄使い」な点も自己採点ポイントが高いものになっています(笑):

上記リンク先の、2016 年に公開した当初は PHP で実装していました。その時のソースコードはこちらです:
https://github.com/dotnsf/Manholizer
このコードはこれはこれで現在も動く(注 Visual Recognition API の古いものを使っているので、顔ハメはうまく動きません)ものですが、いくつかの課題もありました。その1つが「スマホからの利用を想定していなかった」という致命的な点です。見た目でのスマホのウェブブラウザ最適化という意味では実現したつもりでしたが、想定外だったのは「スマホのカメラで撮影した画像の解像度が予想以上に高かった&今後は更に高くなることが想定される」ということです。
ある程度詳しい人には常識かもしれませんが、iPhone をはじめとする最近のスマートフォンのカメラはかなり高い解像度の写真を撮影することができます(特に設定を変更しない場合は、高解像度撮影が標準機能になっていることが多いです)。撮影した写真を低解像度にしてメールで送る、といったことは可能ですが、内部的には高解像度のまま保存されていることになります。これは1枚の写真画像のファイルサイズが非常に大きいということを意味しています。これは2つの点で問題になります。
1つはアプリケーションサーバー側の制約を受ける可能性があるという点です。例えば PHP を普通にインストールしたアプリケーションサーバーの場合、アップロードサイズは 2MB に設定されることが多いです。もちろんこの設定を変更できればいい話ですが、最近は PaaS などでミドルウェア設定を変更できないケースもあるので、そうなるとこの制約を受けてしまいます。
もう1つは API 側の仕様上の制約を受ける可能性です。このマンホライザーでは画像から顔の位置を認識・特定する必要があるのですが、その部分に IBM Watson の Visual Recognition API を使っています。この API の制約として現在は「画像は 2MB まで」という制約があるのでした。つまり上記のアプリケーションサーバー側の制約を取り除いただけでは解決にならないことも出てきてしまうのです。
上記で紹介した、以前作った PHP 版のマンホライザーにはこれら2つの課題があり、スマホからの利用を想定すると期待通りに動かないケースが出てきてしまいました。というわけで、ミドルウェアや設計段階から見直したマンホライザーを作り直すことにしたのでした。
上記2点を解決するため、まず PHP のアップロードファイルサイズ制約をうけないよう、アプリケーションサーバーは Node.js を使うことにしました。PHP から Node.js への移植を行いました。これによって 2MB を超える画像もアップロードできるようにしました。
また API 側のサイズ制約については、アップロードした画像を一旦内部的にリサイズし、API が実行できるレベルにまでサイズを減らしてから実行する、というロジックに変更することで対処しました。細かい点ですが、画像を小さくしてから実行するため、API からのレスポンスは「小さくなった画像に対する顔の位置」になります。アプリケーション側ではアップロードした画像のプレビューが表示されており、その画像にマンホールの位置とサイズを調整して「ハメる」わけですが、元の画像サイズに対するレスポンスにはなっていないので、その辺りも考慮する必要が生じます。
そんなこんなの変更を加えてできあがったのがこちらです:
https://manholizer.mybluemix.net/
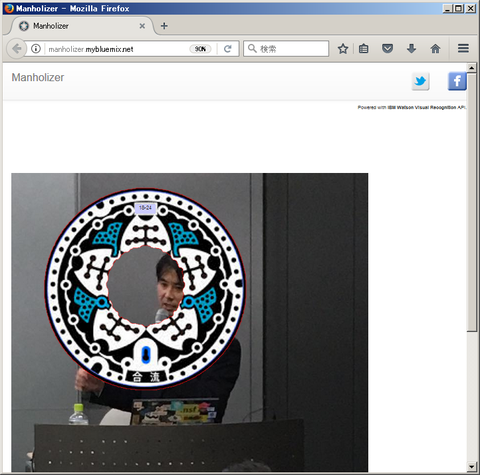
↑ちとズレてるが・・・
使い方は PC またはスマホのウェブブラウザでアプリケーションサーバー(https://manholizer.mybluemix.net/ とか)にアクセスしてください。で、「参照」ボタンをクリック:

手元のローカルファイルシステムまたはフォトライブラリ等から画像ファイルを選択します。今回は「フリー素材アイドル」の Mika x Rika さんの画像を使わせていただきました:

この画像を指定して、しばらく待つと・・・

こんな感じになりました:
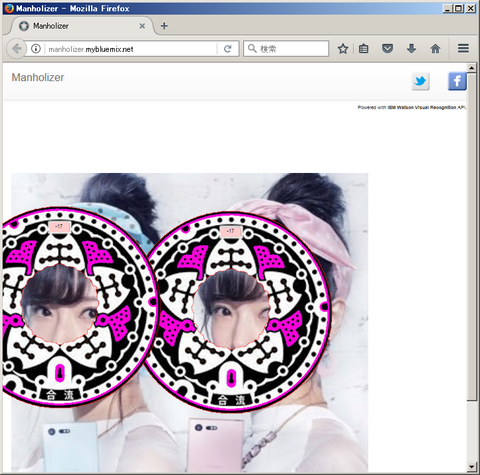
合成用マンホールのデザインとして使っているのは(マンホーラーであればおなじみの)東京都マンホールです:

(2つの)顔の位置を識別し、うまく顔ハメになるようマンホールの位置と大きさが調整されて合成されています。またマンホールの色がピンクなのは「女性」であると認識されている様子です(男性の場合は青いマンホール画像を合成します)。また2人の上部に "-17" と表示されていますが、これは推定年齢でふたりとも「17才以下」であると推測されている、ということを意味しています(お二人の年齢は存じ上げませんが、全体的に日本人の顔は若く判定される傾向があるようです):

なお、このサービスのソースコードはこちらで公開しています。興味ある方はご自身の環境でもどうぞ:
https://github.com/dotnsf/manholizerDemo
自分の環境に導入して使いたい場合の方法は README.md にも記述していますが、IBM Bluemix の Node.js ランタイムで使う場合であれば、まず Bluemix にログインして、SDK for Node.js ランタイムを1つ作成します(この時の名前を後で使います)。また Visual Recognition サービスインスタンスを生成し、その API KEY を取得しておきます(この値も後で使います)。
次に上記サイトからソースコードをダウンロード&展開するか git clone して、以下の2ファイルを編集します。
1つ目は settings.js です。この中の exports.vr_apikey の値に、上記で取得した自分の Watson Visual Recognition サービスの API Key の値を設定します(以下は API Key が abcdabcdabcdabcdabcdabcd であった場合の例です):
もう1つは manifest.yml です。この中を実際に運用するランタイムの情報に設定します。例えば eu-gb リージョンを使って、my_manholizer という名前のランタイムで運用する場合は以下のようになります(ng リージョンの場合、domain は変更せずにそのままで構いません):
この状態で cf コマンドを使ってアプリケーションを push すると、作成した Node.js ランタイム上にマンホライザーがデプロイされます:
IBM Bluemix を使わずに運用する場合は・・・ まあ普通に Node.js をインストールして npm install して使ってください(適当)。
http://dotnsf.blog.jp/archives/1048853473.html
マンホライザーはわかりやすく言うと「マンホール顔ハメ画像作成サービス」です(わかりやすいか??)。先日のマンホールサミット 2017 埼玉に参加した際にも、こんなアナログな顔ハメ写真サービスを提供させていただいたのですが、意外と人気があったのでした。それをウェブ上からもできるようにしよう、というわけで生まれたサービスでした。IBM Watson の画像認識機能を使って実装しており、「テクノロジーの無駄使い」な点も自己採点ポイントが高いものになっています(笑):

上記リンク先の、2016 年に公開した当初は PHP で実装していました。その時のソースコードはこちらです:
https://github.com/dotnsf/Manholizer
このコードはこれはこれで現在も動く(注 Visual Recognition API の古いものを使っているので、顔ハメはうまく動きません)ものですが、いくつかの課題もありました。その1つが「スマホからの利用を想定していなかった」という致命的な点です。見た目でのスマホのウェブブラウザ最適化という意味では実現したつもりでしたが、想定外だったのは「スマホのカメラで撮影した画像の解像度が予想以上に高かった&今後は更に高くなることが想定される」ということです。
ある程度詳しい人には常識かもしれませんが、iPhone をはじめとする最近のスマートフォンのカメラはかなり高い解像度の写真を撮影することができます(特に設定を変更しない場合は、高解像度撮影が標準機能になっていることが多いです)。撮影した写真を低解像度にしてメールで送る、といったことは可能ですが、内部的には高解像度のまま保存されていることになります。これは1枚の写真画像のファイルサイズが非常に大きいということを意味しています。これは2つの点で問題になります。
1つはアプリケーションサーバー側の制約を受ける可能性があるという点です。例えば PHP を普通にインストールしたアプリケーションサーバーの場合、アップロードサイズは 2MB に設定されることが多いです。もちろんこの設定を変更できればいい話ですが、最近は PaaS などでミドルウェア設定を変更できないケースもあるので、そうなるとこの制約を受けてしまいます。
もう1つは API 側の仕様上の制約を受ける可能性です。このマンホライザーでは画像から顔の位置を認識・特定する必要があるのですが、その部分に IBM Watson の Visual Recognition API を使っています。この API の制約として現在は「画像は 2MB まで」という制約があるのでした。つまり上記のアプリケーションサーバー側の制約を取り除いただけでは解決にならないことも出てきてしまうのです。
上記で紹介した、以前作った PHP 版のマンホライザーにはこれら2つの課題があり、スマホからの利用を想定すると期待通りに動かないケースが出てきてしまいました。というわけで、ミドルウェアや設計段階から見直したマンホライザーを作り直すことにしたのでした。
上記2点を解決するため、まず PHP のアップロードファイルサイズ制約をうけないよう、アプリケーションサーバーは Node.js を使うことにしました。PHP から Node.js への移植を行いました。これによって 2MB を超える画像もアップロードできるようにしました。
また API 側のサイズ制約については、アップロードした画像を一旦内部的にリサイズし、API が実行できるレベルにまでサイズを減らしてから実行する、というロジックに変更することで対処しました。細かい点ですが、画像を小さくしてから実行するため、API からのレスポンスは「小さくなった画像に対する顔の位置」になります。アプリケーション側ではアップロードした画像のプレビューが表示されており、その画像にマンホールの位置とサイズを調整して「ハメる」わけですが、元の画像サイズに対するレスポンスにはなっていないので、その辺りも考慮する必要が生じます。
そんなこんなの変更を加えてできあがったのがこちらです:
https://manholizer.mybluemix.net/

↑ちとズレてるが・・・
使い方は PC またはスマホのウェブブラウザでアプリケーションサーバー(https://manholizer.mybluemix.net/ とか)にアクセスしてください。で、「参照」ボタンをクリック:

手元のローカルファイルシステムまたはフォトライブラリ等から画像ファイルを選択します。今回は「フリー素材アイドル」の Mika x Rika さんの画像を使わせていただきました:
この画像を指定して、しばらく待つと・・・

こんな感じになりました:
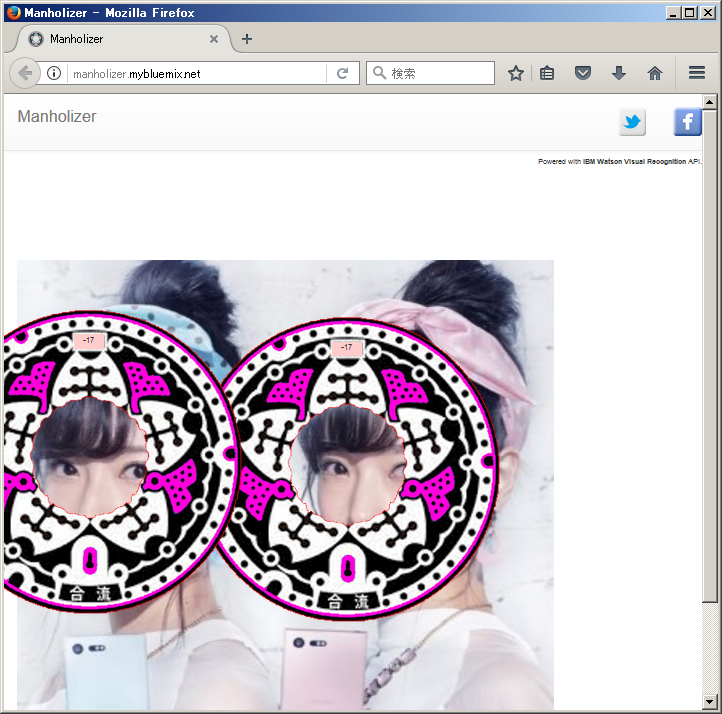
合成用マンホールのデザインとして使っているのは(マンホーラーであればおなじみの)東京都マンホールです:
(2つの)顔の位置を識別し、うまく顔ハメになるようマンホールの位置と大きさが調整されて合成されています。またマンホールの色がピンクなのは「女性」であると認識されている様子です(男性の場合は青いマンホール画像を合成します)。また2人の上部に "-17" と表示されていますが、これは推定年齢でふたりとも「17才以下」であると推測されている、ということを意味しています(お二人の年齢は存じ上げませんが、全体的に日本人の顔は若く判定される傾向があるようです):
なお、このサービスのソースコードはこちらで公開しています。興味ある方はご自身の環境でもどうぞ:
https://github.com/dotnsf/manholizerDemo
自分の環境に導入して使いたい場合の方法は README.md にも記述していますが、IBM Bluemix の Node.js ランタイムで使う場合であれば、まず Bluemix にログインして、SDK for Node.js ランタイムを1つ作成します(この時の名前を後で使います)。また Visual Recognition サービスインスタンスを生成し、その API KEY を取得しておきます(この値も後で使います)。
次に上記サイトからソースコードをダウンロード&展開するか git clone して、以下の2ファイルを編集します。
1つ目は settings.js です。この中の exports.vr_apikey の値に、上記で取得した自分の Watson Visual Recognition サービスの API Key の値を設定します(以下は API Key が abcdabcdabcdabcdabcdabcd であった場合の例です):
(settings.js)
: exports.vr_apykey = 'abcdabcdabcdabcdabcdabcd'; :
もう1つは manifest.yml です。この中を実際に運用するランタイムの情報に設定します。例えば eu-gb リージョンを使って、my_manholizer という名前のランタイムで運用する場合は以下のようになります(ng リージョンの場合、domain は変更せずにそのままで構いません):
(manifest.yml)
: domain: eu-gb.mybluemix.net name: my_manholizer host: my_manholizer :
この状態で cf コマンドを使ってアプリケーションを push すると、作成した Node.js ランタイム上にマンホライザーがデプロイされます:
$ cf push
IBM Bluemix を使わずに運用する場合は・・・ まあ普通に Node.js をインストールして npm install して使ってください(適当)。










